گروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشیگروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشیآموزش اجرای آزمون فریدمن در SPSS
آزمون فریدمن (Friedman) برای طرح های درون گروهی (نمونه های وابسته) مناسب است. آزمون فریدمن تعمیم یافته آزمون ویلکاکسون است و معادل ناپارامتریک آزمون اندازه های مکرّر است. در این آزمون ما یک گروه از افراد یا آزمودنی داریم که در حداقل دو وضعیت یا دو مقطع زمانی مختلف موردسنجش قرار گرفته اند.
- هدف این است که تغییرات نمرات (میانه) را در چند (۲ و بیشتر) وضعیت یا مقطع زمانی مقایسه کنیم.
- سطح سنجش متغیر در این آزمون باید ترتیبی باشد.
- پژوهشگران عموما از این آزمون جهت رتبه بندی یا اولویت بندی متغیرها استفاده می کنند.
این آزمون زمانی بکار می رود که مقیاس اندازه گیری حداقل در سطح مقیاس ترتیبی باشد. این آزمون مشابه کروسکال والیس است، با این شرط که K گروه نمونه جور شده باشند.
توان آزمون فریدمن در مقایسه با قویترین آزمون پارامتری برای K گروه مستقل یعنی آزمون F یکسان است. آزمون فریدمن برای تجزیهء واریانس دوطرفه (برای داده های ناپارامتری) از طریق رتبه بندی به کار می رود.
مثال:
پژوهشی با هدف تعیین و رتبه بندی“مهم ترین ویژگی های اساتید دانشگاه“در دانشگاه شیراز انجام شد و در آن از ۱۰۰ دانشجوی دکتری دانشگاه شیراز پرسیده شد که نظر خودشان را در ارتباط با هرکدام از ویژگی های مطرح شده اساتید در پرسشنامه ابراز کنند. از دانشجویان پرسیده شد که تا چه حد به هرکدام از ویژگی های اساتید اهمیت می دهند؟ پنج ویژگی مطرح شده در ارتباط با اساتید عبارتند از: تسلط علمی، اخلاق خوب در روابط با دانشجویان، ظاهر مرتب و آراسته، فن بیان مناسب و رعایت انصاف در نمره دهی. دانشجویان به هرکدام از ویژگی های مطرح شده در قالب طیف ۱۱ گزینه ای (از ۰ تا ۱۰ که نمره بالاتر به معنای اهمیت بیشتر است) نمره دادند.
بر این اساس سوال زیر طرح و آزمون شد:
کدام ویژگی های اساتید اهمیت بالاتری برای دانشجویان دارد؟
با استفاده از آزمون فریدمن سوال مطرح شده را ارزیابی میکنیم.
نحوه اجرا:
مسیر زیر را دنبال میکنیم:
Analyze —>Nonparametric Tests —>Legacy Dialogs —>K Related Samples
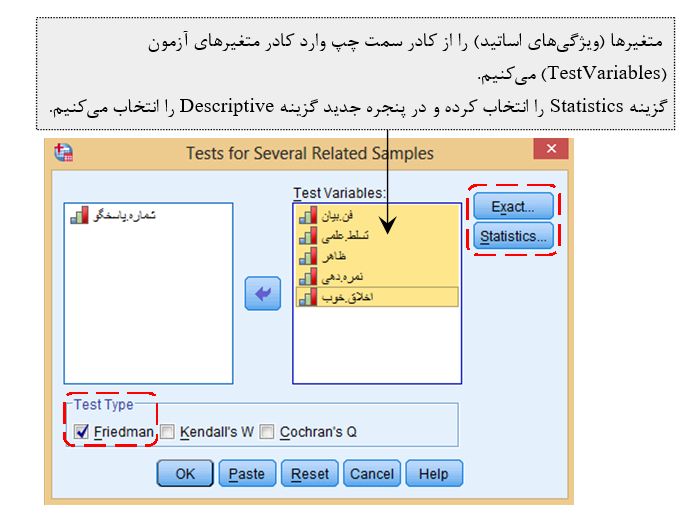
نتیجه بدست آمده:
در جدول بعد میانگین و انحراف استاندارد متغیرها ارائه شده است. دامنه میانگین از ۰ تا ۱۰ است.
| Descriptive Statistics | |||||
| N | Mean | Std. Deviation | Minimum | Maximum | |
| فن بیان | ۱۰۰ | ۴٫۹۹ | ۱٫۸۳ | ۲ | ۹ |
| تسلط علمی | ۱۰۰ | ۴٫۴۸ | ۱٫۶۶ | ۲ | ۱۰ |
| اخلاق خوب | ۱۰۰ | ۵٫۰۱ | ۱٫۷۹ | ۲ | ۱۰ |
| انصاف در نمره دهی | ۱۰۰ | ۷٫۷۹ | ۱٫۵۵ | ۵ | ۱۰ |
| ظاهر آراسته | ۱۰۰ | ۳٫۳۱ | ۲٫۰۱ | ۰ | ۸ |
جدول زیر وضعیت رتبه بندی متغیرها (ویژگیهای اساتید) را نشان می دهد.
| Ranks | |
| Mean Rank | |
| فن بیان | ۳ |
| تسلط علمی | ۲٫۵۶ |
| اخلاق خوب | ۲٫۹۳ |
| انصاف در نمره دهی | ۴٫۵۸ |
| ظاهر آراسته | ۱٫۹۴ |
- که قبل از تفسیر جداول دیگر نخست باید نتایج این جدول را ارزیابی کرد و در صورت معنی دار بودن آزمون فریدمن، به تفسیر نتایج جداول توصیفی و میانگین رتبه بپردازیم.
- این جدول معنی داری آماری را نشان می دهد. مقدار مجذور کای به دست آمده برابر با ۱۶۳٫۷ است که در سطح خطای کمتر از ۰۵/. قرار دارد (۰۵/.>P).
- معنی دار بودن آزمون فریدمن بدین معناست که رتبه بندی ویژگیهای اساتید از نظر دانشجویان بامعناست و دانشجویان رتبه بندی متفاوتی از ویژگی های اساتید دارند.
Test Statisticsa | |
N | ۱۰۰ |
Chi-Square | ۱۶۳٫۷۵ |
df | ۴ |
Asymp. Sig. | ۰۰۰٫ |
a. Friedman Test | |
گزارش:
از آزمون فریدمن برای رتبه بندی مهم ترین ویژگی های اساتید استفاده شد. آزمون فریدمن نشان داد که اهمیت و رتبه ویژگی های مطرح شده در مورد اساتید با یکدیگر متفاوت است(۰۰۱/. >P، ۴ = df، ۱۶۳٫۷۴= مجذور کای).
مقایسه میانگین رتبه ها نشان میدهد که مهم ترین ویژگی اساتید از نظر دانشجویان به ترتیب ویژگی انصاف در نمره دهی، فن بیان مناسب و اخلاق خوب در روابط با دانشجویان است. میانگین رتبه این ویژگی ها به ترتیب ۴٫۵۸، ۳ و ۲٫۹۳ است(میانگین رتبه همه ویژگیها را در یک جدول گزارش کنید).
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
همه چیز درباره آزمون T مستقل در spss
آزمون T مستقل
آزمون T مستقل به ارزیابی مسئله ها می پردازد که آیا میانگین یا معدل دو گروه یا دو وضعیت از لحاظ آماری تفاوتی با هم دارند یا نه.
این آزمون، از آزمونهای قدرتمند محسوب میشوند که برای دادههای پارامتری و دادههایی که معمولاً توزیع میشوند استفاده میگردند.
نکته:
از آزمونهای t برای تحلیل آزمایشات ساده یا انجام مقایسات ساده بین سطوح متغیر وابسته استفاده میشود.
آزمون t بر دو قسم است:
۱) آزمون t وابسته ۲) آزمون t اندازهگیری مکرر( که به آن آزمون t نمونههای جفت یا مرتبط نیز گفته میشود)
تعریف آزمون t وابسته:
در صورتی که شما دو گروه جدا از افراد یا موردهایی را در یک طرح بین شرکتکنندگان (مثل زن و مرد، گروه آزمایش و کنترل) داشته باشید استفاده میشود.
تعریف آزمون t اندازهگیری مکرر( که به آن آزمون t نمونههای جفت یا مرتبط نیز گفته میشود):
در شرایطی استفاده میشود که شرکت کنندگان دادههایی برای تمام سطوح و وضعیت متغیر مستقل در یک طرح درون-شرکت کنندگان ارائه میدهند (مثلاً قبل یا بعد از مداخله).
در این نوشته آموزش آزمون t مستقل را فرا خواهیم گرفت. در مطلب دیگری به آزمون t اندازهگیریهای مکرر پرداخته خواهد شد. دلیل اینکه به این دو موضوع به طور جداگانه خواهیم پرداخت این است که فایل دادهها متفاوت از هم هستند، از آپشنهای منو جداگانه در SPSS استفاده میکنند، و خروجی متفاوت از هم دارند. در نمونههای زیر نشان میدهیم که پس از ایجاد فایل دادهها چه اتفاقی رخ میدهد.
استفاده از آزمون t مستقل در SPSS
این خودآموز به شما میگوید که چگونه آزمون t مستقل را اجرا یا تفسیر کنید.
مثال براساس مطالعۀ شوتلند و استراو (۱۹۷۶) میباشد. این افراد درصدد بودند تا تأثیر رابطۀ دریافتی بین نزاع یک زوج بر احتمال مداخلۀ شخص دیگر را کشف کنند.
برای آزمون این مسئله شرکتکنندگان به دو گروه تقسیم شدند و از آنها خواسته شد تا فیلم نزاع دو شخص را تماشا کنند.
فیلمها به جز برای یک خط تعیینکننده مشابه هم بود. یک گروه فریاد زدن قربانی را میبیند که می گوید” تنهایم بگذار، تو را نمیشناسم”. در حالی که گروه دیگر همان شخص را میبیند که میگوید” تنهایم بگذار، نباید با تو ازدواج میکردم”.
از شرکتکنندگان خواسته شد تا میزان مداخلۀ خود را براساس مقیاس ۱-۵ ارزیابی کنند. دادهها را میتوان به شرح زیر در فایل SPSS گنجاند:
“داده های هفته ۶ file.sav’: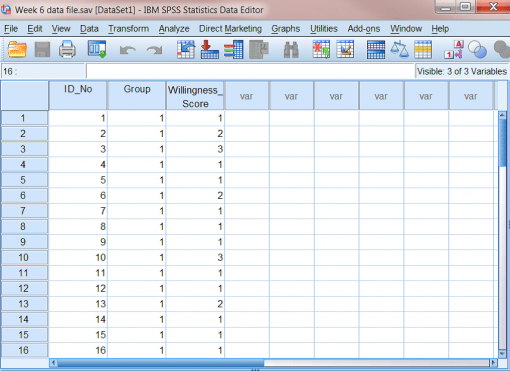
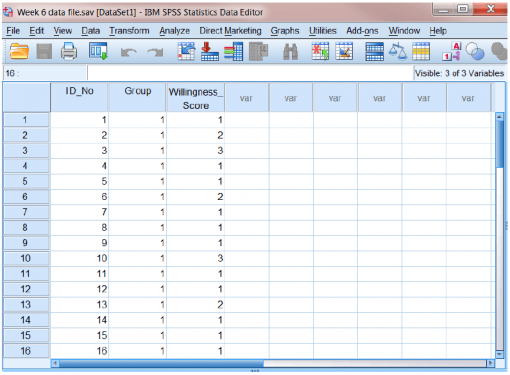
برای آزمون t مستقل، فایل داده ها باید دارای حداقل دو ستون باشد:
– یک ستون برای متغیر مستقل
– یک ستون برای متغیر وابسته
- متغیر مستقل از کدها برای اختصاص دادن عضویت گروه به هر سطح یا وضعیت استفاده می کند. به عنوان مثال، از “۱” برای گروه کنترل و “۲” برای گروه آزمایشی می کند. هر ستون، متغیر متفاوتی را به نمایش می گذارد و هر ردیف حاوی داده های یک شرکت کننده است. ستون های مختلف داده های زیر را نشان می دهد
- متغیر ID_No به شماره شناسۀ اختصاص یافته به هر شرکت کننده اشاره دارد. ما از اعداد به عنوان شناساگر به جای اسامی شرکت کنندگان استفاده می کنیم. این شیوه کمک می کند تا داده ها را بدون اینکه نام شرکت کنندگان فاش شود گردآوری کنیم. این شیوه در روانشناسی بویژه زمانی که گردآوردی داده ها با حاسیت زیاد مواجه است بسیار مفید و کاربردی است.
تعریف متغییر مستقل:
گروه متغیر به ما می گوید که شرکت کنندگان در چه وضعیت آزمایشی قرار دارند که به آن متغیر مستقل گفته می شود. IV برای آزمون t مستقل همیشه داده های مطلق (یا اسمی) است.
مثال :
ما از کد “۱” برای شرکت کنندگانی استفاده کردیم که زوج در حال نزاع را با هم غریبه در نظر گرفتند و کد “۲” برای کسانی که بین آنها رابطه ایی لحاظ کردند. در SPSS، به این کدها صفحۀ Variable View گفته می شود. برای آشنایی با این کدها به خودآموز اول با عنوان افزودن متغیرها مراجعه کنید.
Willingness_Score یک نوع رتبه بندی خودسنجی است که به این می پردازد که شرکت کنندگان تا چه اندازه مایل به مداخله در نزاعی که شاهدش هستند می باشند. این متغیر وابسته ما می باشد. در مثالی که بیان کردیم، این نمره یا اسکور با استفاده مقیاس ۵ امتیازی لیکرت رتبه بندی می شود که مقیاس بالاتر نشانگر احتمال بیشتر مداخله می باشد.
همانطور که در ابتدای خودآموز گفته شد، آزمون t مستقل، نمرات دو گروه را بر اساس یک متغیر خاص با هم مقایسه می کند.
- در این مورد، می خواهیم نمرات رضایت و میل دو گروه آزمایشی را با هم مقایسه کنیم.
برای آغاز تحلیل، ابتدا بایدد روی منوی Analyze کلیک کنیم، - گزینۀ Compare Means
- و سپس گزینۀ فرعی Independent-Samples T Test را انتخاب کنیم.
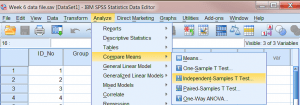
پس از آن کادر دیالوگ Independent Samples T-Test باز می شود.
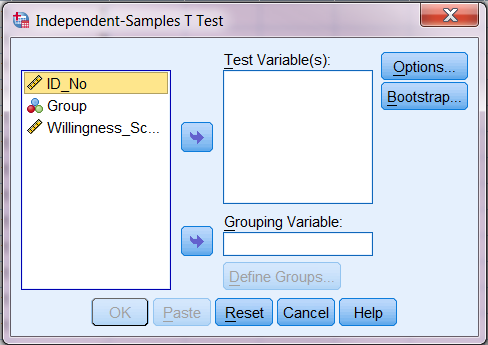
در اینجا باید به SPSS بگوییم که قصد داریم کدارم متغیرها را تحلیل کنیم. شاید متوجه شوید که متغیرهای شما در حال حاضر در پنجرۀ چپ قرار دارند.
به محض اینکه Variable Labels(برچسب های متغیر) نمایش داده شد، به جز Variable Names (اسامی متغیر) کوتاهتر، خواندن بقیه دشوار است.
برای تغییر این وضعیت، با موس روی پنجره کلیک راست کنید و گزینۀ نمایش را به شرح زیر به ‘Display Variable Names’ تغییر دهید:
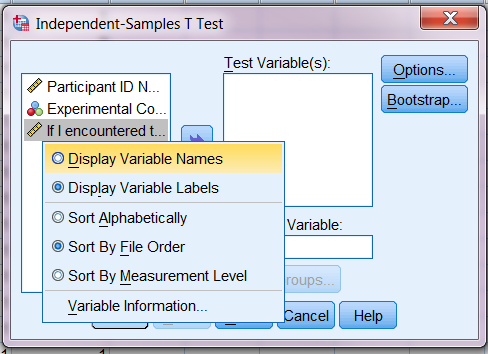
بدین ترتیب لیست متغیر تغییر می کند و خواندن آن راحت تر می شود.
اکنون می توانید کار تحلیل را شروع کنید. ابتدا، باید به SPSS بگوید که Grouping Variable (یا IV) شما چیست.
برای ای کار، متغیر Group را SELECT یا انتخاب کنید و سپس آن را با استفاده از پیکان آبی در قسمت پایین کنار کادر Grouping Variable به قاب پایینی سمت راست ببرید.
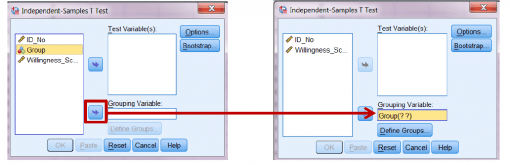
Groupاکنون دو علامت سئوال در کنار خود دارد. این به این معنی است که باید به SPSS بگویید کدام وضعیت ها را می خواهید مقایسه کنید.
همین که وضعیت های IV (دسته بندی های گروهی) با کدهای عددی وارد SPSS شد، باید به SPSS بگویید کدام کدها وضعیت هایی را که می خواهید مقایسه کنید نشان می دهد.
با کلیک روی دکمۀ Define Groups می توانید این کار را انجام دهید.
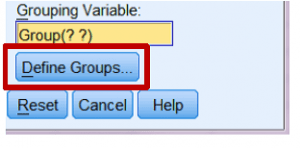
پس از این کادر دیالوگ Define Groups باز می شود و می توانید کدهای عددی را برای هر وضعیت آزمایشی که دارید مقایسه می کنید وارد کنید.
در این مورد، ما از “۱” برای کسانی که زوج را غریبه و از “۲” برای کسانی که زوج را دارای رابطه می دانستند استفاده می کنیم.
بدین ترتیب، باید اعداد ۱ و ۲ را به کادرهای ورودی Group 1 و Group 2 که در اینجا نشان داده می شود اضافه می کنیم.
بعد از آنکه هر دو عدد را وارد کردیم دکمۀ ادامه را باید فعال کنیم. برای ادامه روی continue کلیک کنید.
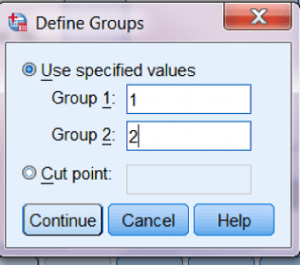
اکنون باید به SPSS بگویید می خواهید کدام متغیر وابسته را به تحلیل اضافه کنید.
برای این کار، Willingness_Score را انتخاب کنید
و روی دکمۀ پیکان بالایی کلیک کنید تا متغیر به پنجرۀ Test Variable(s) اضافه شود.
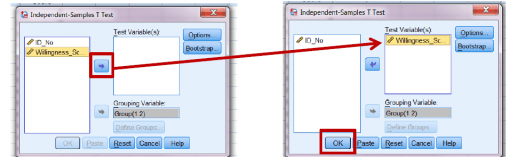
اکنون هر دو متغیر اضافه شده اند. برای اجرای تحلیل، روی OK کلیک کنید.
پنجرۀ خروجی به شما این امکان را می دهد که نتایج آزمون t را بررسی کنید: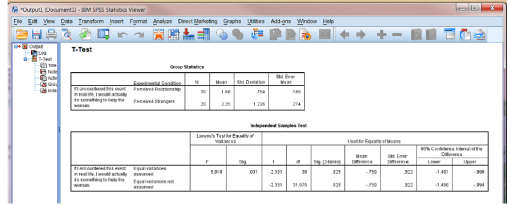
توجه داشته باشید که خروجی دارای دو قسمت است.
این دو قسمت موارد زیر را نشان می دهد:
۱) آمار توصیفی
۲) آمار استنتاجی
بهتر است نگاهی دقیق تر به کادرهای خروجی بیندازیم.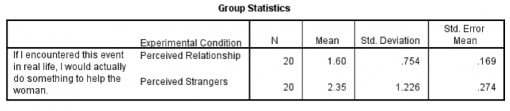
آمار گروهی
- کادر اول آمار توصیفی گروه ها را نشان می دهد. قبل از اینکه هر کار دیگری انجام دهید، بهتر است همیشه اول این کادر را بررسی کنید. با این کار می توانید به نگرش اولیه به طرح داده های خود دست یابید.
- در این جدول می توانید مشاهده کنید که میانگین نمره یا اسکور رضایت برای شرکت کنندگان در وضعیت رابطۀ دریافتی ۱٫۶۰ و در وضعیت غریبۀ دریافتی ۲٫۳۵ است. علاوه بر این، از انحراف معیار مشخصاست که تغییر داده ها (یعنی گسترش نمرات) برای گروه غریبه ها کمی (SD=1.23) بیشتر از گروه رابطه (SD=0.75) است.
این شیوه ای استاندارد برای گزارش آمارهای توصیفی در شرایطی که می خواهید نتایج خود را گزارش دهید می باشد. در نتیجه، با نکاهی به میانگین های خود مشاهده می کنید که به طور متوسط شرکت کنندگانی که تصور می کردند زوج در حال نزاع با هم رابطه دارند احتمال اینکه تمایل به مداخله داشته باشند از شرکت کنندگان که زوج را با هم غیبه می دانستند کمتر بود.
اما چگونه باید تفاوت بین میانگین ها را تفسیر کرد؟ برای پی بردن به اینکه آیا از لحاظ آماری تفاوتی بین نمرات وجود دارد ، در مرحله بعد باید نگاهی به جدول آمار استنتاجی بیندازید. 
آزمون نمونه های مستقل
این جدول آمار استنتاجی شما را نشان می دهد: خروجی آزمون t مستقل. نیازی نیست در خصوص تمام ستون های اینجا خود را نگران کنید( بسیاری از قسمت های جدول فقط برای سطح پیشرفته لازم است).
بخش های کلیدی جدول در قسمت بالا مشخص شده است و در قسمت زیر توضیح داده خواهد شد:
– آزمون لون برابری واریانس ها:
یکی از فرضیات آزمون t مستقل این است که دو گروهی که با هم مقایسه می کنید دارای پراکندگی نمرات مشابه هستند. (در غیراینصورت با عنوان همگنی یا برابری واریانس تلقی می شوند).
این ستون ها به ما می گویند که آیا مورد همین است یا نه.
چنانچه مقدار F معنی دار باشد، این وضعیت نشان می دهد که تفاوت های معنی دار آماری در شیول پراکندگی داده ها وجود دارد و با فرض همگنی مطابقت نداشته است.
توجه داشته باشید که جدول خروجی دارای دو ردیف است:
وقتی واریانس ها با هم برابر باشند از یکی استفاده می کنیم و وقتی برابر نباشند از ردیف دیگر استفاده می کنیم. در این نمونه، نمی توانیم واریانس ها را با هم برابر فرض کنیم. زیرا مقدار F معنی دار است (p = .031). بدین ترتیب، ما فقط باید مقادیر ردیف دوم جدول را بخوانیم.
آزمون t برابری میانگین ها:
در این ستون آمار آزمون t وجود دارد. این بخش به هفت بخش فرعی تقسیم می شود. اما فقط سه ستون در این مرحله مهم هستند. این سه ستون عبارتند از labelled t، df و sig (دنباله ای).
در این موقعیت شما تعیین می کنید که آیا فرضیۀ مورد آزمون تأیید شده است یا نه.
– مقدار t بدست آمده از t: این مقدار آمار آزمون t است که SPSS ماسبه کرده است. هر چه مقدار t بیشتر باشد، احتمال اینکه نتایج بصورت تصادفی رخ داده باشد کمتر است.
پیش از اینکه از کامپیوتر برای تحلیل داده ها استفاده شود، مقدار t به صورت دستی با استفاده از فرمول محاسبه می شد. مقدار به دست آمده سپس با مقدار بحرانی در جدولی به نام توزیع توزیع t مقایسه میشد. SPSS ما را از انجام همۀ این کارها معاف کرد.
درجۀ ازادی df:
در اکثرآزمون های آماری با درجۀ ازادی مواجه خواهید شد. درجۀ آزادی مقداری است که از آن برای نمایش اندازۀ نمونه یا نمونه های مورد استفاده در یک آزمون آماری استفاده می شود و باید حتما گزارش شود.
شیوۀ گزارش درجۀ آزادی در ازمون های آماری مختلف متفاوت است. اما باید قبل از اینکه معنی داری نتیجه آزمون بررسی شود به دقت و درستی محاسبه گردد. زیاد نگران این مسئله نباشید. SPSS خود به بصورت خودکار مقدار آن را برایتان محاسبه می کند. اما باید توجه کنید که مقدار df با آزمون های مختلف tهمیشه نزدیک به تعداد کل شرکت کنندگان است.
Sig (دو دنباله ای):
میزان معنی داری (که به آن احتمال یا مقدار p) نیز می گویند در مورد این احتمال به ما می گوید که آیا نتایج بصورت تصادفی رخ داده است یا نه. در صورتی که این مقدار کمتر از .۰۵ باشد، فرضیه تأییدد می شود. در صورتی که بیشتر باشد، فرصیه بخاطر صفر یا خنثی بودن رد می شود که به معنی این است که هیچ تفاوتی بین دو گروه وجود ندارد.
در خصوص آزمون t مستقل،نرمافزار SPSS آزمون را در میزان معنی داری دو دنباله ای به صورت پیش فرض می سنجد. برای دستیابی به احتمال یک دنباله ای ( در صورتی که فرضیه یک جهتی باشد) مقدار p به نصف تقسیم می شود. در این موقعیت، می توانیم یک فرضیۀ یک دنباله ای مورد آزمون قرار دهیم مبنی بر اینکه افرادی که فکر می کردند بین زوج در حال نزاع رابطه ای وجود دارد احتمال اینکه در نزاع مداخله کنند از کسانی که خلاف این تصور می کردند کمتر خواهد بوداگر این کار را می کردیم، مقدار p 0.013 می شد (۱ دنباله ای).

برای بررسی خروجی به چه چیزی نیاز داریم؟
هنگامی که نتایج آزمون t را یادداشت می کنید، باید از طریق فرمول زیر مشخص کنید که آیا آزمون معنی دار بوده یا نه:
t (df) = t value, p = p value
در این فرمول اعداد مربوطه را در قسمت هایی که زیر آن خط کشیده شده وارد کنید. در مورد این مثال خاص، متوجه شدیم که آزمون t معنی دار است. ارزش p کمتر ۰٫۰۵ (p< .05) است.
t(31.58) = -2.33, p = 0.026
یافته ها چه چیزی به ما می گویند؟
زمانی که میخواهید یافته های خود را تفسیر و یادداشت کنید باید از اطلاعات هر دو آمار توصیفی و استنتاجی استفاده کنید. ترتیب ارائۀ این دو آمار اصلا مهم نیست. اما همیشه کار خود را با تفسیر واضح نتایج داده ها به پایان برسانید.
- مرحلۀ اول: می توانید طرح داده های خود را با استفاده از میانگین و انحراف معیار اولین جدول خروجی توصیف کنید. در این مورد، می توانید به صورت زیر تفسیر خود را بنویسید:
– نتایج نشان داد شرکت کنندگانی که متوجه رابطۀ بین زوج شدند نمرۀ تمایل کمتری (M=1.60, SD=.75) از کسانی که متوجه رابطه نشدند (M=2.35, SD=1.22) داشتند. - مرحلۀ دو: از حروف و اعداد برای گزارش رسمی اختلاف معنی دار یا غیرمعنی دار استفاده کنید.
آزمون t مستقل نشان داد که این طرح معنی دار است t(31.58) = -2.33, p < 0.05. - مرحلۀ سه: در پایان، برای تفسیر و خلاصه سازی آنچه از فرضیه اتان متوجه شده اید باید این اطلاعات را در کنار هم قرار دهید. این مسئله را باید به انگلیسی(فارسی) سلیس بنویسید: مثال:
روی هم رفته، این آزمون نشان می دهد که رابطۀ دریافتی بین قربانی و مرتکب بر تمایل شرکت کنندگان به مداخله تأثیر می گذارد و فرضیه را تأیید می کند.
اکنون شما یاد گرفته اید که چگونه با استفاده ازنرم افزار SPSS آزمون T مستقل را انجام دهید.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
سطح معنی داری آماری و خطاهای آماری در spss
تعریف آمار:
روشهائی برای جمع آوری، تنظیم و تجزیه و تحلیل اطلاعات عددی درباره یک موضوع مشخص که بصورت زیر میباشد.
– طرح نمونه گیری یا آزمایشات: آن دسته از علم آمار را گویند که با جمعآوری اطلاعات یا طرح آزمایشات سروکار دارد.
– آمار توصیفی: آن دسته از علم آمار را گویند که با دستهبندی و تلخیص دادها سروکار دارد.
– آمار استنباطی: آن دسته از علم آمار را گویند که باتجزیه و تحلیل و نتیجه گیری از دادهها سروکارر دارد.
۱٫ طرح نمونه گیری یا آزمایشات:
نمونه، بخشی از جامعهی تحت بررسی است که با روشی از پیش تعین شده انتخاب میشود که میتوان از این بخش، استنباطهایی درباره کل جامعه انجام داد.
به دلایل زیر از نمونهگیری به جای سرشماری کل جامعه استفاده میشود:
– کاهش هزینه
– افزایش سرعت کار
– بالا بودن توان کار
– بالا بودن میزان درستی کار
– پرهیز از خراب کردن واحدهای جامعه
انواع روشهای نمونهگیری: آموزش نرم افزار SPSS
الف) روش احتمالی:
همه افراد جامعه از شانس مساوی برای انتخاب شدن برخوردارند. این روش جنبه علمی دارد.
ب) روش غیر احتمالی:
همه افراد شانس مساوی ندارند جنبه علمی هم ندارد. در پایاننامه استفاده نمیشود. مانند روش سهمیهبندی، اتفاقی، قضاوتی، هدفدار و غیره.
الف)روش احتمالی:
۱- تصادفی:
۱٫۱ – ساده: تعداد افراد را داریم ولی اطلاعات و مشخصات آنها را نداریم.
۲٫۱ – سیستماتیک: فرض کنید جامعهای به حجم N تحت بررسی باشد و واحدهای جامعه را از ۱ تا N شماره گذاری کنند.
۲- خوشهای: دراین روش، خوشههای جامعه را از ۱ تا N شمارهگذاری و سپس n خوشه را به تصادف انتخاب میکنیم.
۲٫۱-یک مرحلهای: اگر مشخصهی همهی واحدهای موجود در این n خوشه را اندازه بگیریم، دنبالهای از اندازه ها بدست میآید که آن را نمونه گیری خوشهای یک مرحلهای مینامیم.
۲٫۲- دو مرحلهای: اگر از هر n خوشه تعدادی انتخاب کنیم، آن را نمونه گیری خوشهای دو مرحلهای میگویند.
۳- طبقهبندی شده: در نمونه گیری با طبقهبندی، طبقات الزاماً باید همگن باشند، اما چنین الزامی در اینجا نیست.طبقهبندی از نظر جنس، سن، سال، برند و غیره
روشهای تعین حجم نمونه
۱- جدول مورگان: ساده تریین روش استفاده از جدول مورگان است
تعریف سطح معنی دار در spss
قدم بعدی مشخص کردن درجه ای برای معنی دار بودن تفاوت ها و حجمی برای نمونه مورد بررسی است.
روش کار این است که فرض را به نفع فرض رد می کنیم به شرط اینکه از یک آزمون آماری مقداری به دست آوریم که احتمال وقوع آن مقدار با توجه به برابر یا کمتر از یک احتمال بسیار کوچک باشد، که با نشان داده می شود، باشد و به آن؛ «سطح معنی داری» (significance level) گفته می شود.
مقادیری که معمولا برای استفاده می شود اکثرا ۰٫۰۱ و۰٫۰۵ است.
از انجا که مقدار α در تعیین اینکه باید رد شود یا نه دخالت مستقیم دارد، الزام رعایت عینیت در تحقیق ایجاب می کند که را پیش از شروع جمع آوری داده ها مشخص کنیم.
سطح معنی داری که محقق برای تعیین در تحقیق α انتخاب می کند براساس تخمین او از اهمیت و یا درجۀ قابلیت کاربرد یافته هایش مبتنی است.
طبیعی است که اگر تحقیق مثلا درباره آثار درمانی عمل جراحی روی مغز باشد، محقق باید α را خیلی کمتر در نظر بگیرید زیرا خطرهای رد کردن نادرست فرضیه صفر بسیار زیاد است.
هنگام اتخاذ تصمیم دربارۀ H0 ممکن است دو نوع خطا پیش آید:
خطای نوع اول (Type I): رد کردن فرض H0 در حالی که درست است.
خطای نوع دوم (Type II): پذیرفتن فرض H0در حالی که غلط است.
احتمال وقوع خطای نوع اول با α ارتباط دارد، هر چهα بزرگتر شود، احتمال اینکه H0 را به غلط رد کنیم یا به عبارت دیگر، احتمال اینکه مرتکب خطای نوع اول شویم، افزایش می یابد.
خطای نوع دوم معمولا باβ نشان داده می شود.
حروف لاتینα و β هم برای نشان دادن «نوع خطاها» و هم «ارتکاب خطاها» به کار می روند، یعنی: (رد کردن H0 وقتی H0 درست است) P = (خطای نوع اول) P =α (رد نکردن H0 وقتی H0 غلط است ) P = (خطای نوع دوم) P=β احتمالα به مقدار مشخص پارامتر در دامنه ای بستگی داد که H0 آن را در بر می گیرد و حال آن که β به مقدار پارامتر در دامنه ای بستگی داد که H1آن را در بر می گیرد.
این خطاها و احتمال آن ها در رابطه با H0 را می توان به صورت جدول ۱-۴ خلاصه کد.
 واضح است که بین α وβ رابطه معکوس وجود دارد. با بالا رفتنα مقدار β کاهش می یابد و برعکس.
واضح است که بین α وβ رابطه معکوس وجود دارد. با بالا رفتنα مقدار β کاهش می یابد و برعکس.
این رابطه در آمار به «بده – بستان» (Trade off)بینα و β معروف است.
آن چه مسلم است، مجموعα وβ الزاما عدد یک نیست.
واضح است که در هر استنباط آماری، احتمال وقوع یکی از این دو نوع خطا وجود دارد و لازم است که آزمون کننده به نوعی سازش که تعادل بین احتمال وقوع این دو نوع خطا را به حد مطلوب برساند دست یابد.
آزمون های آماری مختلف، احتمال تعادل های مختلفی را عرضه می کنند.
در رسیدن به چنین تعادلی است که موضوع «توان آزمون» (Power Function) مطرح می شود.
توان آزمون عبارت است از احتمال رد H0 وقتی که H0 حقیقتا نادرست است: β-۱ = (احتمال وقوع خطای نوع دوم) – ۱ = توان آزمون آن چه موجب کاهش «خطای نوع اول»، « خطای نوع دوم» و همچنین «توان آزمون» می شود، افزایش حجم نمونه است.
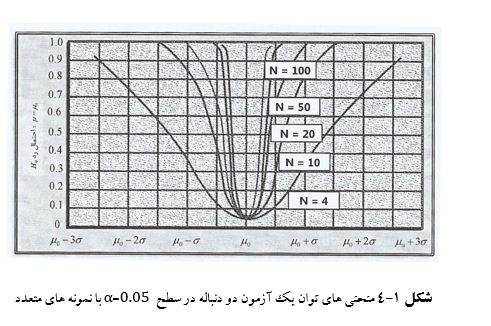
منحنی های شکل ۱-۴ نشان می دهد که وقتی حجم نمونه (n) افزایش می یابد احتمال وقوع خطای نوع دوم (β)کاهش می یابد.
در اینجا افزایش «توان آزمون» دو طرفۀ میانگین وقتی حجم نمونه افزایش می یابد با هم مقایسه شده است.
مشاهده می شود که وقتی حجم نمونه از ۴ به ۵۰٫۲۰٫۱۰ و۱۰۰ افزایش می یابد، چگونه توان آزمون نیز زیادتر می شود.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
آموزش نحوه نرمال سازی داده ها در spss
آموزش گام به گام نحوه نرمال کردن داده ها در spss
در انجام بسیاری از تحلیل های آماری،توزیع نرمال نقش اساسی ایفا می کند در این روش ها به بررسی نرمال نرمال کردن یا همان نرمالیزه کردن داده ها در اس پی اس اس می پردازیم و کمی زمان بر تر از سایر دستورات گفته شده این نرم افزار می باشد.
این سؤال خیلی از هموطنان است که می پرسند استانداردسازی دادهها چه فایده ای دارد؟
پاسخ این است که استانداردسازی دادهها کمک میکند که اهمیت آنها به واحد اندازهگیریشان بستگی نداشته باشد. در نتیجه در مواردی مانند دادهکاوی و تحلیل دادههای چند متغیره از دادههای استاندارد شده استفاده میشود. همچنین استانداردسازی برای دادههای کمی و کیفی قابل اجرا است و چند روش استانداردسازی وجود دارد.
در بسیاری از روشهای آماری نرمال بودن متغیر وابسته یکی از فروض اصلی بشمار میرود که زیر به برخی روشهای معمول نرمال سازی اشاره شده است.
۱- وارون سازی داده ها: وارون کردن همه مشاهدات : در صورت عدم مشاهده صفر
۲- لگاریتم(LOG): محاسبه لگاریتم همه مشاهدات : در صورت منفی نبودن مشاهدات
۳- ریشه دوم: محاسبه ریشه دوم همه مشاهدات: در صورت منفی نبودن مشاهدات
۴- تبدیل جانسون(Johnson Transformation) : سیستم تبدیل جانسون بر مبنای سه توزیع Bounded system(SB) و Log-normal system (SL) و Unbounded system (SU) و برآورد پارامترهای تورزیع های فوق عمل میکند.
بهینه سازی پارامترهای توزیع تا جایی که یکی از توابع تبدیل، بهترین توزیع نرمال را تولید کند ادامه می یابد. الگوریتم انتخاب بهترین توزیع توسط Polansky , Chou در سال ۱۹۹۹معرفی شد. این روش با توجه به علامت جبری داد ه ها روشی مناسب برای نرمال سازی به شمار میرود.
۵- تبدیل باکس کاکس(Box-Cox transformation): این تبدیل یکی از روشهای قدرتمند در نرمال سازی توزیع مشاهدات به شمار میرود. این روش مقداری به عنون توان (λ) تعیین کرده و همه مشاهدات را به توان آنمیرساند و سپس ازمون نرمال روی مشاهدات انجام شده تا بهترین سری از مشاهدات بدست آید.مقدار λ بین –۵ تا ۵ تغییر میکند.این روش فقط برای داده های مثبت به کار میرود و این تنها نقطه ضعف این روش است.
آموزش مرحله به مرحله نرمال سازی داده ها در spss:
مرحله۱- داده ها را وارد محیط نرم افزار spss می کنیم. در این مرحله می توان داده ها را به صورت دستی وارد کرد و یا از محیط دیگری مثل اکسل داده ها را کپی کرد.
 مرحله۲- پس از اینکه داده ها را وارد کردید به تب Analyze رفته و وارد قسمت Descriptive Statistics و Explore شوید.
مرحله۲- پس از اینکه داده ها را وارد کردید به تب Analyze رفته و وارد قسمت Descriptive Statistics و Explore شوید.
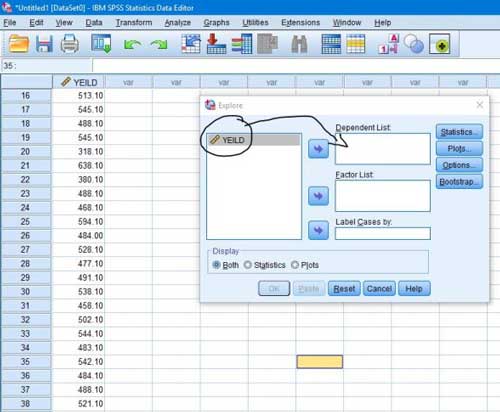
 مرحله۳- در پنجره باز شده، صفت مورد نظر را وارد کادر Dependent List می کنیم. در این مرحله اگر چند صفت داشته باشیم می توانیم آزمون نرمال بودن را به صورت همزمان روی همه صفات انجام دهیم بنابراین همه صفات را وارد کادر Dependent List می کنیم.
مرحله۳- در پنجره باز شده، صفت مورد نظر را وارد کادر Dependent List می کنیم. در این مرحله اگر چند صفت داشته باشیم می توانیم آزمون نرمال بودن را به صورت همزمان روی همه صفات انجام دهیم بنابراین همه صفات را وارد کادر Dependent List می کنیم.
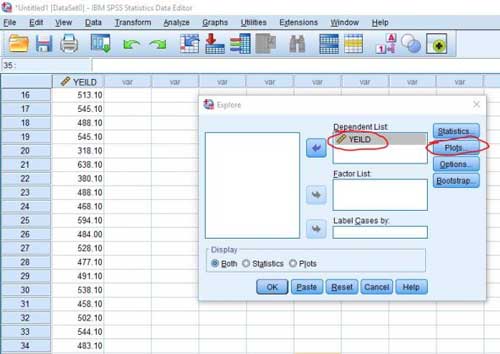
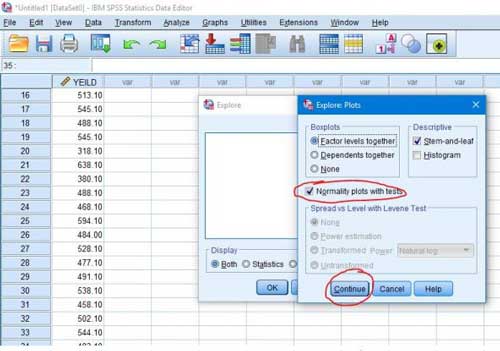
 مرحله۴- پس از وارد کردن صفات باید از قسمت Plots تیک عبارت Normality plots with tests را فعال و روی دکمه Continue و Ok کلیک می کنیم تا نتایج آزمون در پنجره Output ظاهر شود.
مرحله۴- پس از وارد کردن صفات باید از قسمت Plots تیک عبارت Normality plots with tests را فعال و روی دکمه Continue و Ok کلیک می کنیم تا نتایج آزمون در پنجره Output ظاهر شود.
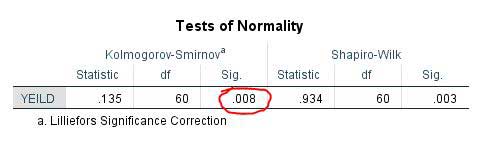
 مرحله ۵- مشاهده کردید که چگونه براحتی با دو آزمون، نرمال بودن داده ها بررسی شد. اکنون طبق گفته های بالا، نتایج آزمون کولموگروف-اسمیرنوف را بررسی می کنیم. در این جدول اگر مقدار sig. بیشتر از ۰٫۰۱ باشد داده ها نرمال و اگر کمتر از ۰٫۰۱ باشد داده ها توزیع نرمال ندارند و باید آنها را قبل از تجزیه واریانس تبدیل بکنیم.
مرحله ۵- مشاهده کردید که چگونه براحتی با دو آزمون، نرمال بودن داده ها بررسی شد. اکنون طبق گفته های بالا، نتایج آزمون کولموگروف-اسمیرنوف را بررسی می کنیم. در این جدول اگر مقدار sig. بیشتر از ۰٫۰۱ باشد داده ها نرمال و اگر کمتر از ۰٫۰۱ باشد داده ها توزیع نرمال ندارند و باید آنها را قبل از تجزیه واریانس تبدیل بکنیم.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
تحلیل همبستگی پیرسون و همبستگی اسپیرمن در SPSS
تعریف تحلیل همبستگی پیرسون و همبستگی اسپیرمن در SPSS
تحلیل همبستگی پیرسون و همبستگی اسپیرمن از پرکاربردترین و سادهترین تحلیلها در SPSS هستند. پژوهشگران دو تحلیل را به شما معرفی خواهند کرد.
گاهی اوقات پژوهشگری علاقه دارد بداند که چه رابطهای بین دو متغیر وجود دارد.
برای مثال:
آیا بین میزان بارش در ۱۰ نقطه با میزان رشد گیاهان در این ۱۰ نقطه رابطهای وجود دارد یا خیر. یا اینکه آیا بین میزان افسردگی افراد با میزان عزت نفس فرد رابطهای وجود دارد یا نه. برای این منظور میتوان از آزمونهای همبستگی استفاده کرد. آزمونهای همبستگی به دو دسته کلی پارامتریک (تحلیل همبستگی پیرسون) و ناپارامتریک (تحلیل همبستگی اسپیرمن) تقسیم میشوند. البته چند تحلیل همبستگی ناپارامتریک دیگر نیز وجود دارد که به دلیل کاربرد کم در اینجا توضیحی درباره آنها ارائه نخواهد شد.
تفاوت تحلیل همبستگی پیرسون و همبستگی اسپیرمن
برای بررسی همبستگی باید حداقل دو متغیر داشته باشید. اگر دادههای شما در سطح فاصلهای یا نسبی باشند مانند نمره افسردگی، شادکامی، سن، قد، میزان پرش یک ورزشکار و … از تحلیل همبستگی پیرسون استفاده خواهد شد. همچنین اگر دادههای شما به صورت رتبهای باشند مانند تحصیلات، سال ورود به دانشگاه، مرتبه شغلی و … از تحلیل همبستگی اسپیرمن استفاده خواهد شد.
نکته مهم:
برخی از متغیرها را میتوان هم به صورت فاصلهای یا نسبی به کار برد و هم به صورت رتبهای. برای مثال اگر شما سن آزمودنیهای خود را به صورت عدد (برای مثال ۲۶، ۲۷، ۲۸) ثبت کرده باشید این متغیر فاصلهای است اما اگر به صورت طیف قرار داده باشید (برای مثال ۰ تا ۱۰ سال، ۱۰ تا ۲۰ سال، ۲۰ تا ۳۰ سال) در این صورت این متغیر رتبهایی است.
ضریب همبستگی چه معنایی دارد؟
ضریب همسبتگی همیشه عددی بین ۱ تا ۱- است. ضریب همبستگی بین ۰ تا ۱ به معنی داشتن همبستگی مثبت است و هرچه این ضریب به ۱ نزدیکتر باشد همبستگی قویتر است. همبستگی مثبت یعنی با افزایش نمره یک متغیر نمره متغیر دیگر نیز افزایش مییابد، مثلاً با افزایش نمره افسردگی نمره اضطراب نیز افزایش مییابد. ضریب همبستگی بین ۰ تا ۱- به معنی داشتن همبستگی منفی بین دو متغیر است و هرچه عدد به ۱- نزدیکتر باشد یعنی همبستگی منفی قویتر است. همبستگی منفی یعنی با کاهش نمره یک متغیر نمره متغیر دیگر کاهش مییابد، مثلاً با افزایش افسردگی میزان شادکامی کاهش مییابد.
نحوه تفسیر ضریب همبستگی
در بالا گفتیم که ضریب همبستگی بین ۱ تا ۱- است. اما اعداد این ضریب چه معنایی دارند؟ برای مثال ضریب همبستگی ۰٫۴۷ نشان دهنده ارتباط قوی بین دو متغیر است یا ارتباط ضعیف؟ برای تفسیر ضریب همبستگی میتوان از راهنمای زیر استفاده کرد که در بسیاری از کتابهای آماری آمده است:
– ضریب بین ۰ تا ۰٫۲۹ نشان دهنده همبستگی ضعیف
– ضریب بین ۰٫۳۰ تا ۰٫۶۹ نشان دهنده همبستگی متوسط
– ضریب بین ۰٫۷۰ تا ۱ نشان دهنده همبستگی قوی
برخی از موضوعاتی که با استفاده از تحلیل همبستگی انجام گرفتهاند آورده شده است:
– رابطه بین سلامت روانی با نمره درسی
– رابطه بین جذابیت با اعتماد دیگران به فرد
– رابطه بین رضایت مشتریان از پاسخگویی پرسنل با میزان خرید آنان از فروشگاه
– رابطه بین عزت نفس با ابتلا به بیماری روانی در دانش آموزان
– رابطه بین ساعات استفاده از اینترنت با نمره کسب شده توسط دانشجویان
نحوه اجرای تحلیل همبستگی پیرسون در SPSS
مثال:
فرض کنید که پژوهشگری قصد دارد رابطه بین نمره تحصیلی یک فرد را با میزان اعتیاد اینترنتی او به دست آورد. برای این منظور او نمرات ۲۰ نفر را ثبت میکنید و با استفاده از پرسشنامه اعتیاد اینترنتی، نمره اعتیاد اینترنتی این ۲۰ نفر را نیز به دست میآورد. در ادامه تحلیل مربوط به این مثال را خواهید دید.
در منوی بالای SPSS به این مسیر بروید: Analyze>Correlate<Bivariate
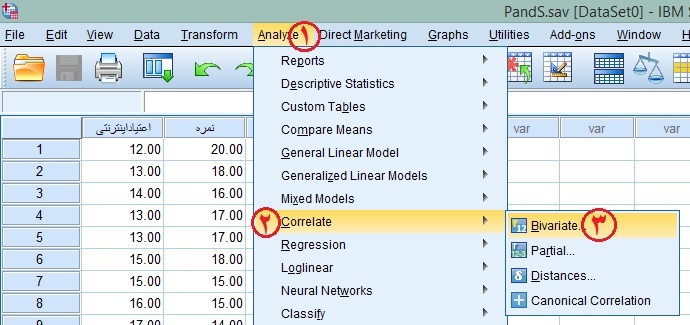
در کادر باز شده دو متغیر خود را انتخاب و از سمت چپ به سمت راست منتقل کنید. سپس تیک گزینه Pearson را زده و سپس Ok را بزنید.
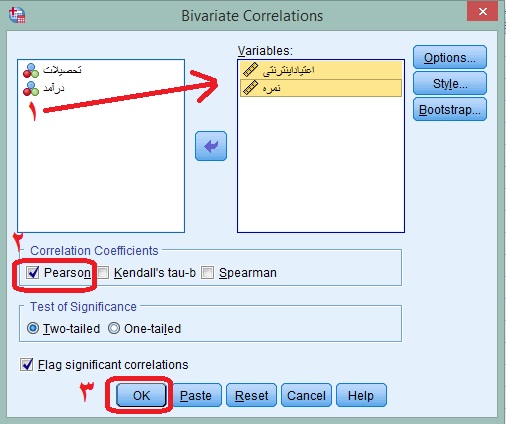 خروجی SPSS برای شما نشان داده خواهد شد.
خروجی SPSS برای شما نشان داده خواهد شد.
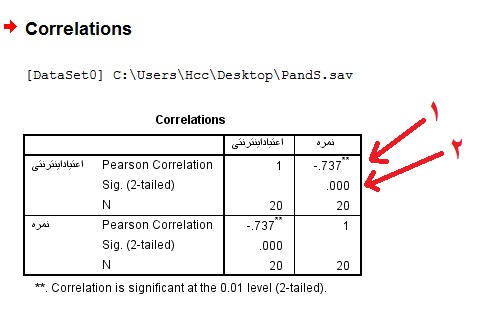 در خروجی ظاهر شده تلاقی سطر اول با ستون دوم با سطر دوم با ستون اول نتایج شما خواهد بود. عدد اول نشان دهنده ضریب همبستگی از که عددی بین ۱ تا ۱- خواهد بود. عدد دوم نشان دهنده معناداری یا P-Value است که اگر کمتر از ۰٫۰۵ باشد نشان دهنده معنی دار بودن رابطه بین دو متغیر است. در اینجا ضریب همبستگی بین نمره افراد با میزان اعتیاد اینترنتی آنان ۰٫۷۳۷- است. این ضریب همبستگی نشان میهد که بین این دو متغیر رابطه همبستگی منفی وجود دارد، یعنی با افزایش اعتیاد اینترنتی نمره فرد کاهش مییابد. همچنین با توجه به میزان Sig یا همان معناداری، مشاهده میشود که رابطه این دو متغیر معنادار میباشد.
در خروجی ظاهر شده تلاقی سطر اول با ستون دوم با سطر دوم با ستون اول نتایج شما خواهد بود. عدد اول نشان دهنده ضریب همبستگی از که عددی بین ۱ تا ۱- خواهد بود. عدد دوم نشان دهنده معناداری یا P-Value است که اگر کمتر از ۰٫۰۵ باشد نشان دهنده معنی دار بودن رابطه بین دو متغیر است. در اینجا ضریب همبستگی بین نمره افراد با میزان اعتیاد اینترنتی آنان ۰٫۷۳۷- است. این ضریب همبستگی نشان میهد که بین این دو متغیر رابطه همبستگی منفی وجود دارد، یعنی با افزایش اعتیاد اینترنتی نمره فرد کاهش مییابد. همچنین با توجه به میزان Sig یا همان معناداری، مشاهده میشود که رابطه این دو متغیر معنادار میباشد.
نحوه اجرای تحلیل همبستگی اسپیرمن در SPSS
مثال۲:
فرض کنید که پژوهشگری قصد دارد رابطه بین میزان تحصیلات و میزان درآمد را بسنجد. برای این منظور او تحصیلات (زیردیپلم، دیپلم، دانشگاهی) و میزان درآمد (۱ تا ۲ میلیون، ۲ تا ۳ میلیون و ۳ تا ۴ میلیون) تعدادی از افراد را گردآوری میکند. تحلیل مربوط به این مثال در زیر آمده است.
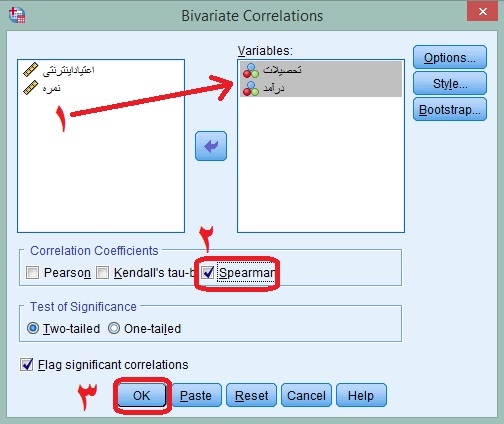
در منوی بالای SPSS به این مسیر بروید:
Analyze>Correlate<Bivariate
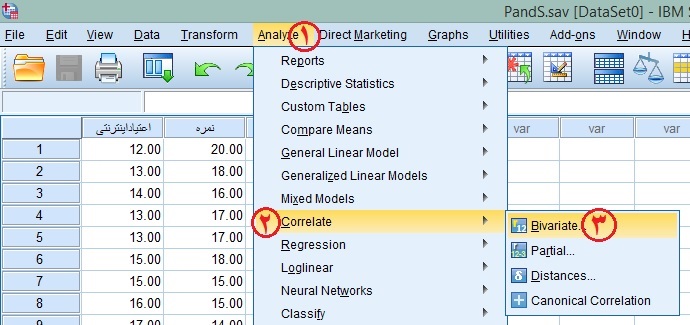
در کادر باز شده دو متغیر خود را انتخاب و از سمت چپ به سمت راست منتقل کنید. سپس تیک گزینه Spearman را زده و سپس Ok را بزنید.
 خروجی SPSS برای شما نشان داده خواهد شد.
خروجی SPSS برای شما نشان داده خواهد شد.
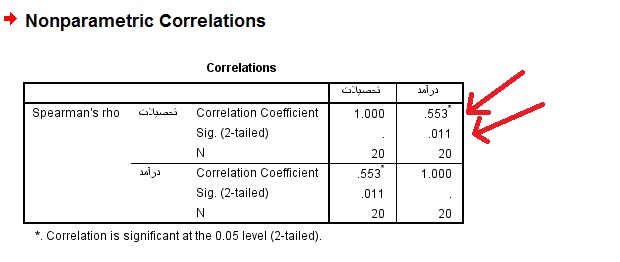 در خروجی ظاهر شده تلاقی سطر اول با ستون دوم با سطر دوم با ستون اول نتایج شما خواهد بود. عدد اول نشان دهنده ضریب همبستگی از که عددی بین ۱ تا ۱- خواهد بود. عدد دوم نشان دهنده معناداری یا P-Value است که اگر کمتر از ۰٫۰۵ باشد نشان دهنده معنی دار بودن رابطه بین دو متغیر است. در اینجا ضریب همبستگی بین نمره افراد با میزان اعتیاد اینترنتی آنان ۰٫۵۵۳ است. این ضریب همبستگی نشان میهد که بین این دو متغیر رابطه همبستگی مثبت وجود دارد، یعنی با افزایش سطح تحصیلات، میزان درآمد نیز افزایش مییابد. همچنین با توجه به میزان Sig یا همان معناداری، مشاهده میشود که رابطه این دو متغیر معنادار میباشد.
در خروجی ظاهر شده تلاقی سطر اول با ستون دوم با سطر دوم با ستون اول نتایج شما خواهد بود. عدد اول نشان دهنده ضریب همبستگی از که عددی بین ۱ تا ۱- خواهد بود. عدد دوم نشان دهنده معناداری یا P-Value است که اگر کمتر از ۰٫۰۵ باشد نشان دهنده معنی دار بودن رابطه بین دو متغیر است. در اینجا ضریب همبستگی بین نمره افراد با میزان اعتیاد اینترنتی آنان ۰٫۵۵۳ است. این ضریب همبستگی نشان میهد که بین این دو متغیر رابطه همبستگی مثبت وجود دارد، یعنی با افزایش سطح تحصیلات، میزان درآمد نیز افزایش مییابد. همچنین با توجه به میزان Sig یا همان معناداری، مشاهده میشود که رابطه این دو متغیر معنادار میباشد.
09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی