گروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشیگروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشیآزمون میانگین نمونه تکی در SPSS
تعریف آزمون میانگین نمونه تکی در SPSS:
با یک نمونه از جامعه آماری سروکار خواهیم داشت. قرار است براساس این نمونه در مورد میانگین جامعه قضاوت انجام گیرد.
فرض کنید به عنوان یک تحلیلگر داده (Data Scientist)، با یک جامعه آماری مواجه شدهاید که میانگین آن مشخص نیست و میخواهید در مورد این میانگین، تحقیق و بررسی انجام دهید و به یک تصمیم برسید.
مثال:
در نظر بگیرید که در یک کارخانه تولیدی لبنیات، شکایاتی مبنی بر کم بودن وزن بستههای پنیر دریافت شده است. مسئولین برای آنکه مشخص کنند آیا شکایات معتبر یا بیدلیل هستند دست به نمونهگیری زدهاند و براساس اطلاعاتی که از وزن بستههای پنیر در نمونه وجود دارد، میخواهند به این تصمیم آماری برسند که آیا دستگاهها احتیاج به تنظیم دارند یا شکایات بیمورد هستند.
پیش فرضهای تحلیل t تک نمونه ای یا تی تک گروهی
۱- توزیع دادهها باید نرمال باشد (با استفاده از آزمون کولموگروف اسمیرنوف).
۲- دادهها باید در مقیاس فاصلهای یا نسبی باشند (ماننده نمره سن، وزن، پرسشنامه و …).
۳- نمره معیار یا ثابتی باشد که بتوانید میانگین خود را با آن مقایسه کنید.
اجرای تحلیل t تک نمونه ای یا تی تک گروهی
فرض کنید نمره افسردگی چند نفر را با پرسشنامه افسردگی بک به دست آوردهاید. طبق دستورالعمل این پرسشنامه افرادی که نمره ۲۰ و بالاتر را کسب کنند دارای افسردگی هستند. حالا شما میخواهید نمرهای که به دست آوردید را با این عدد ثابت ۲۰ مقایسه کنید. برای این کار در منوی بالای SPSS به مسیر زیر بروید:
Analyze>Compare Means>One-Sample T Test
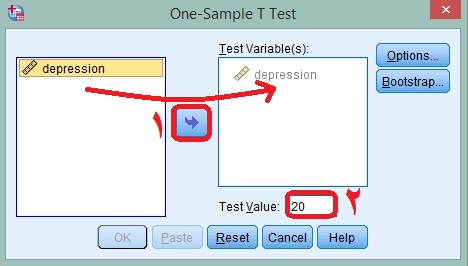
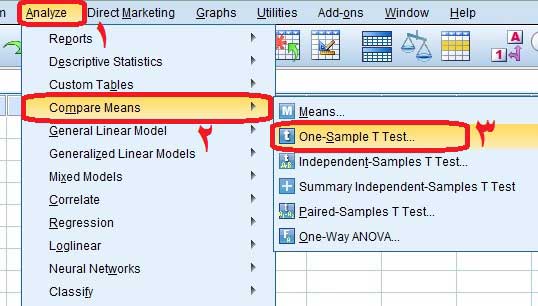 پس از رفتن به مسیر ذکر شده کادر زیر برای شما باز خواهد شد. در کادر زیر نمره افسردگی را از کادر سمت چپ به کادر سمت راست انتقال میدهیم. سپس در کادر Test Value که در شکل زیر با عدد ۲ مشخص شده است نمره ثابت یا معیار را که در اینجا ۲۰ است وارد میکنیم و بر روی گزینه Ok کلیک میکنیم.
پس از رفتن به مسیر ذکر شده کادر زیر برای شما باز خواهد شد. در کادر زیر نمره افسردگی را از کادر سمت چپ به کادر سمت راست انتقال میدهیم. سپس در کادر Test Value که در شکل زیر با عدد ۲ مشخص شده است نمره ثابت یا معیار را که در اینجا ۲۰ است وارد میکنیم و بر روی گزینه Ok کلیک میکنیم.
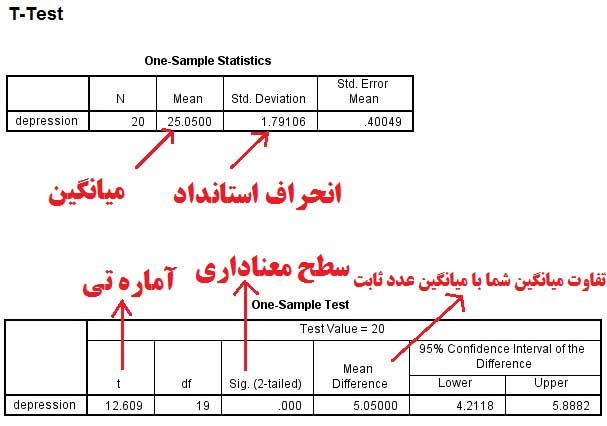
 پس از مرحله بالا خروجی دادهها ظاهر میشود. در بین جداول، نمرات و اعداد مشخص شده به رنگ قرمز موررد نظر ما هستند و در جدول خروجی گزارش میشوند. همانگونه که در جدول زیر مشاهده میشود میانگین به دست آمده از جانب ما از نمره ثابت به طور معناداری بیشتر است.
پس از مرحله بالا خروجی دادهها ظاهر میشود. در بین جداول، نمرات و اعداد مشخص شده به رنگ قرمز موررد نظر ما هستند و در جدول خروجی گزارش میشوند. همانگونه که در جدول زیر مشاهده میشود میانگین به دست آمده از جانب ما از نمره ثابت به طور معناداری بیشتر است.
(نحوه گزارش خروجی تحلیل t تک نمونه ای یا تی تک گروهی در SPSS)
قبل از هر چیز باید از شرایط و فرضیاتی که آزمون میانگین نمونه تکی باید داشته باشد مطلع باشیم. در زیر فهرستی از این فرضیات دیده میشود:
- دادهها کمی (عددی) هستند.
- توزیع جامعه آماری نرمال است.
- واریانس جامعه آماری ثابت ولی نامعلوم است. این پارامتر باید توسط مشاهدات نمونهای محاسبه یا برآورد شود.
نکته:
اگر حجم نمونه کم (حدود ۳۰) و میزان چولگی، کم باشد، باز هم میتوان از آزمون میانگین نمونه تکی برای قضاوت در مورد میانگین جامعه استفاده کرد.
فرضها و آماره آزمون
در انجام آزمون میانگین نمونه تکی، فرضهای صفر و مقابل به صورت زیر در نظر گرفته میشوند:
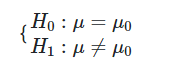
مقدار
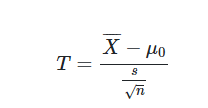
نکته: در نرمافزار SPSS فرضیات، به صورت زیر در نظر گرفته میشوند. ولی به هر حال نتیجه حاصل، در هر دو حالت یکسان خواهد بود.
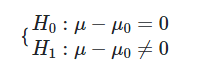
با توجه به خصوصیاتی که مقدار احتمال (p-value) دارد، اگر نتیجه آن برای آزمون کمتر از احتمال خطای نوع اول (α " style="box-sizing: border-box; -webkit-tap-highlight-color: transparent; display: inline-block; line-height: 0; text-align: center; overflow-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; margin: 0px; padding: 1px 0px; position: relative; font-family: IRANSans !important; font-size: 17px !important;">α) یا همان سطح خطای آزمون شود، فرض صفر را رد خواهیم کرد.
شیوه اجرای آزمون میانگین نمونه تکی در SPSS
برای اجرای این آزمون طبق معمول از فهرست Analysis شروع میکنیم سپس گزینه Compare Means و دستور One Sample T-test را انتخاب کرده و پارامترهای آزمون را مطابق تصویرهای زیر تنظیم خواهیم کرد.
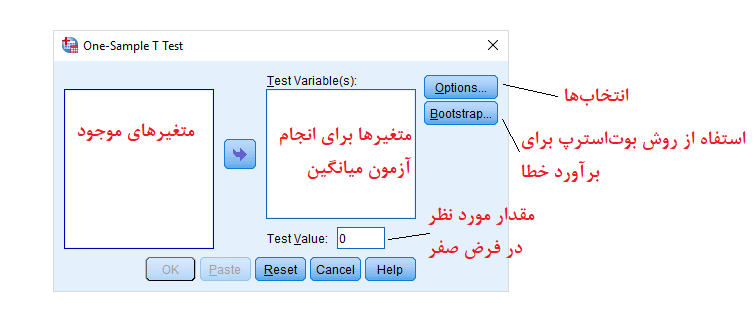
در تصویر زیر هر یک از پارامترهای مربوط به این آزمون، معرفی شدهاند. توجه داشته باشید که متغیرهایی که در قسمت (Test Variable(s قرار میدهید، مقدارهای عددی یا متغیر کمی باشند.
در خروجی این آزمون، یک فاصله اطمینان برای اختلاف میانگین جامعه از
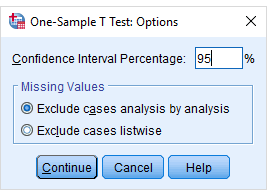
همینطور اگر چندین متغیر را در بخش متغیرهای آزمون قرار دادهاید، با انتخاب گزینه Exclude cases analysis by analysis مشخص میکنید که دادههای گمشده (Missing Values) در هر تحلیل جداگانه در نظر گرفته شود.
برای مثال اگر برای متغیر اول، مشاهده سوم و برای متغیر دوم، مشاهده پنجم دارای مقدار گمشده است، هنگام اجرای آزمون برای متغیر اول، مشاهده سوم و برای آزمون میانگین متغیر دوم، مشاهده پنجم در نظر گرفته نخواهد شد. ولی با انتخاب Exclude cases listwise فقط مشاهداتی در انجام همه آزمونها به کار میروند که مقدار گمشده در هیچ یک از آنها وجود ندارد. بنابراین با انتخاب این گزینه، مشاهده سوم و پنجم در تحلیل به کار نخواهند رفت.
مثال ۲
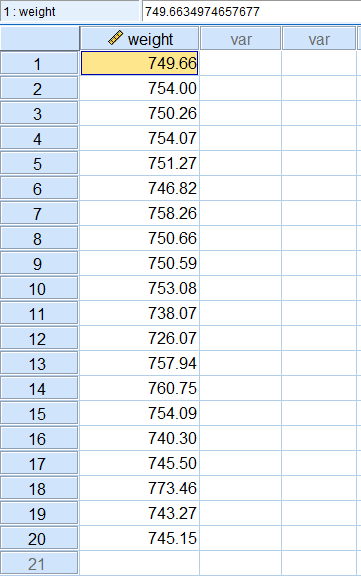
فرض کنید اطلاعات مربوط به وزن ۲۰ بسته ۷۵۰ گرمی پنیر تولیدی در یک کارخانه در اختیار شما قرار گرفته است. باید قضاوت کنید که آیا این نمونه در مورد شکایت مشتریان مبنی بر کم بودن وزن بستهها دلیل خوبی است یا شکایتها بیمورد هستند؟ این اطلاعات را در SPSS مطابق تصویر زیر وارد کردهایم.
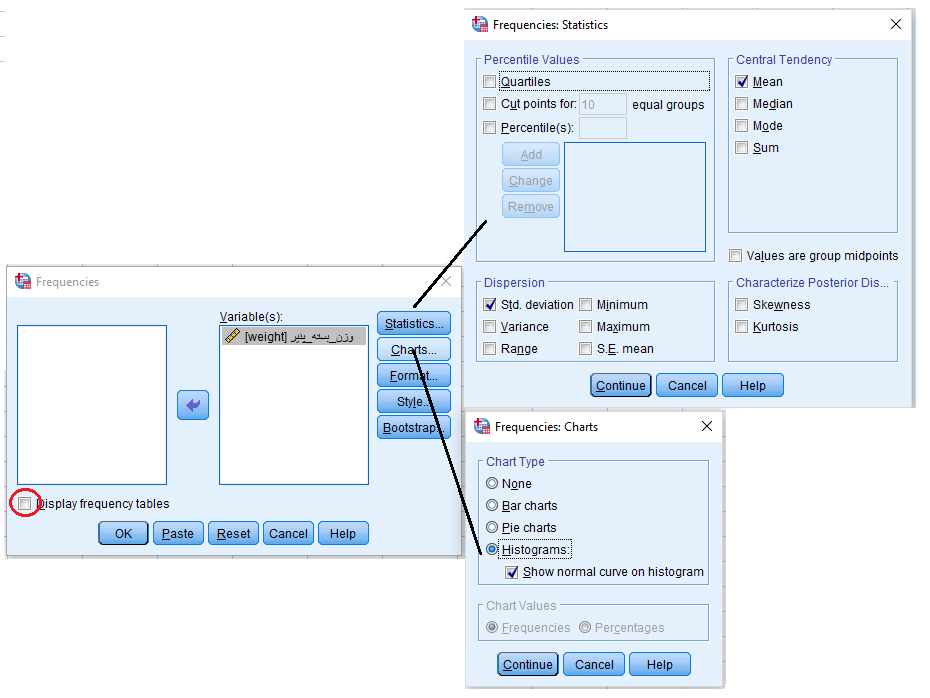
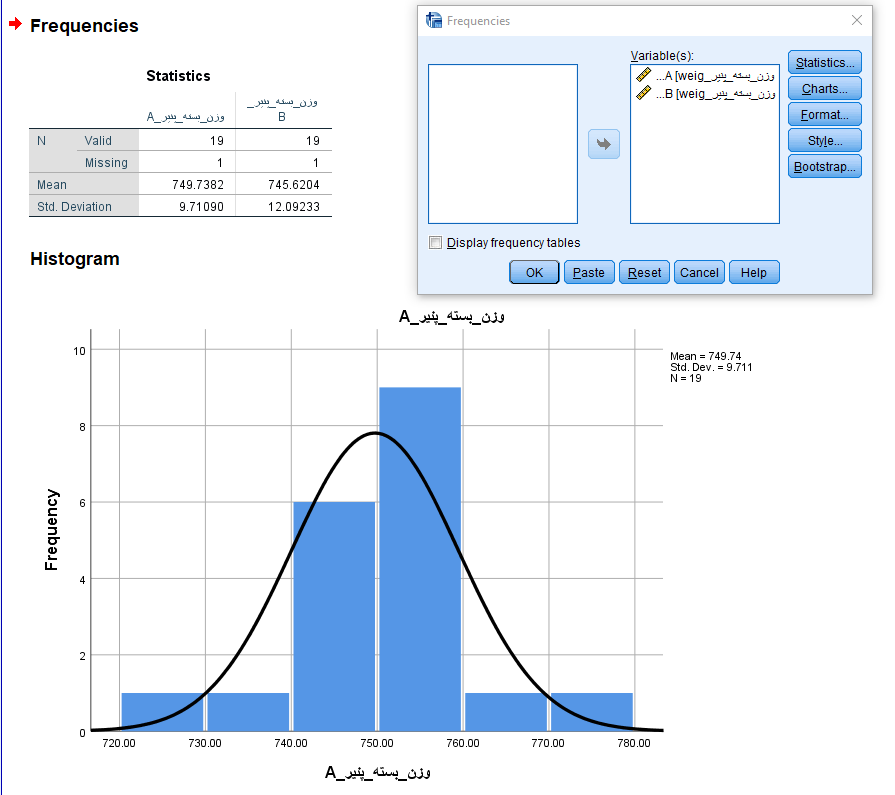
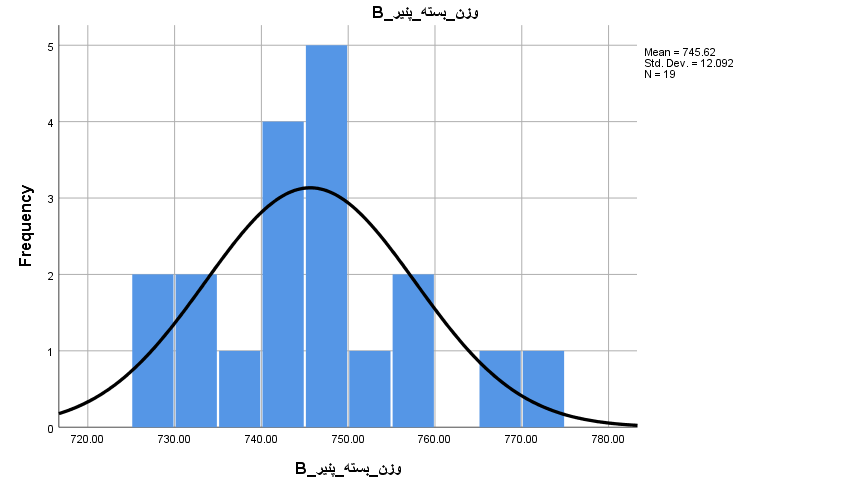
برای آنکه مشخص شود توزیع این دادهها شبیه نرمال هستند، از یک «بافتنگار فراوانی» (Histogram) استفاده میکنیم. برای ترسیم آن از فهرست Analysis گزینه frequency را انتخاب و در پنجره ظاهر شده تنظیمات را مطابق با تصویرهای زیر پیاده میکنیم.
نکته:
از آنجایی که احتیاجی به مشاهده جدول فراوانی وجود ندارد، گزینه display frequency tables را از حالت انتخاب خارج کردهایم.
(خروجی به صورت زیر در خواهد آمد.)
- حال مراحل دسترسی به آزمون میانگین نمونه تکی را طی کرده و پارامترها را مطابق تصویر زیر در پنجره مربوط به آزمون تنظیم میکنیم.
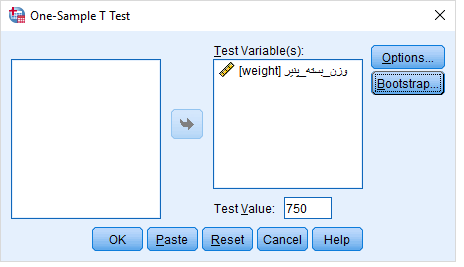
- با فشردن دکمه OK محاسبات صورت گرفته و خروجی مطابق با جدول زیر ظاهر خواهد شد.

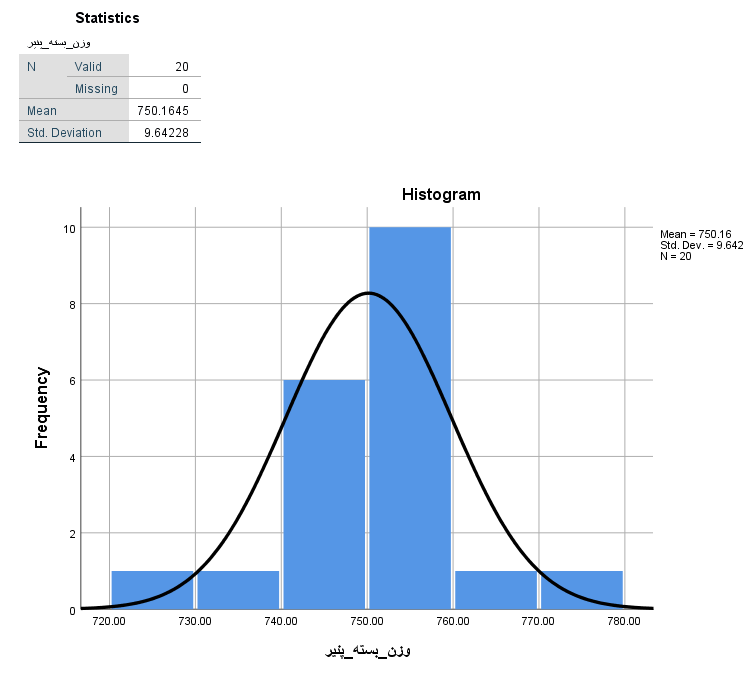
در جدول اول با عنوان One-Sample Statistics،
میانگین نمونه برابر با ۷۵۰٫۱۶۴۵ گرم
با انحراف استاندارد ۹٫۶۴۲۲۸ گرم
خطای استاندارد میانگین نیز برابر با ۲٫۱۵۶۰۸ گرم
مقدار آمار آزمون ۰٫۰۷۶ و درجه آزادی نیز ۱۹ بدست می آید.
با توجه به بزرگ بودن مقدار احتمال (p-Value) که در SPSS با Sig نمایش داده میشود و مقایسه آن با احتمال خطای نوع اول دلخواه
α " style="box-sizing: border-box; -webkit-tap-highlight-color: transparent; display: inline-block; line-height: 0; text-align: center; overflow-wrap: normal; word-spacing: normal; white-space: nowrap; float: none; direction: ltr; max-width: none; max-height: none; min-width: 0px; min-height: 0px; border: 0px; margin: 0px; padding: 1px 0px; position: relative; font-family: IRANSans !important; font-size: 17px !important;">α (که معمولا آن را ۰٫۰۵ در نظر میگیریم)متوجه میشویم که ادعا مشتریان نادرست است چرا؟
زیرا ۰٫۹۴۰ بزرگتر از ۰٫۰۵ است. در نتیجه این نمونه دلیلی بر رد فرض صفر ارائه نکرده است و نمیتوان فرض صفر را رد کرد.
مثال ۳:
.فرض کنید دو نوع محصول A و B در بستههای ۷۵۰ گرمی تولید شوند.
از هر دو محصولات آزمون می گیریم که متوسط وزن بستهها همان ۷۵۰ گرم است.
ولی بنا به دلایلی (مثلا باز بودن بسته بندی و خارج شدن محتویات از بستهها) در هر دو نمونه یک مقدار گمشده وجود دارد.
حال آزمون را با دو وضعیت برای دادههای گمشده اجرا میکنیم. در حالت اول گزینه Exclude cases analysis by analysis را در بخش option فعال کرده و نتایج آزمون را مشاهده میکنیم.
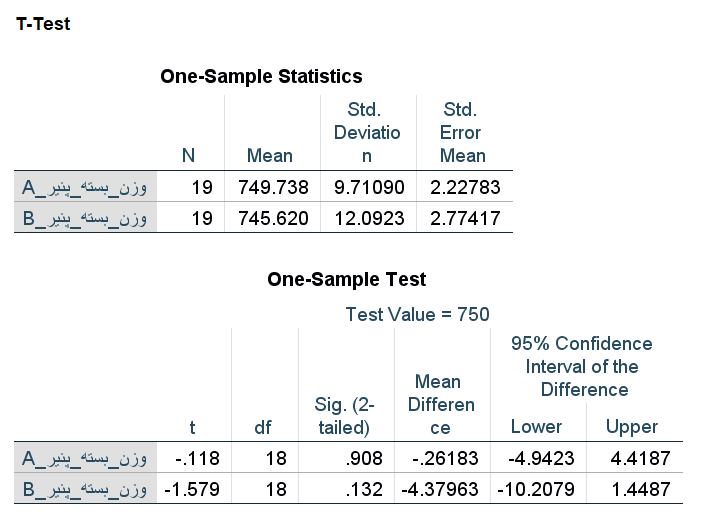
از آنجایی که هر کدام از متغیرها یا ستونها دارای یک مشاهده گمشده بودند، تعداد در جدول اول برابر با ۱۹ ثبت شده است.
همچنین در جدول دومی SIG، فرض صفر در سطح خطای ۰٫۰۵، توسط این نمونهها رد نخواهد شد و به نظر میرسد میانگین وزن بستهها همان ۷۵۰ گرم ادعای کارخانه است.
نکته :اگر لازم باشد که هر دوی مشاهدات گمشده در متغیرها کارخانه لحاظ نشوند چه کار باید انجام داد؟
کافی است که گزینه Exclude cases listwise را از بخش options انتخاب و آزمون را اجرا کنید.
خروجی در این حالت به صورت زیر در خواهد آمد. مشخص است که در جدول اول، تعداد مربوط به هر دو گروه ۱۸ خواهد بود و درجه آزادی (df) مربوط به آماره آزمون هم ۱۷ محاسبه میشود.
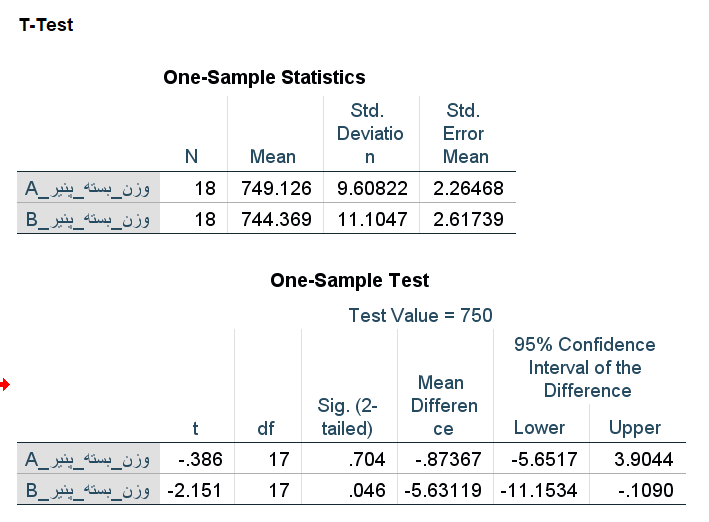
نکتهمهم:تغییر مقدار میانگین در هر دو متغییر فوق:
۱- تعداد مشاهدات متفاوت است، میانگین نیز بر اساس آن تغییر کرده است.
۲-چرا در کار خانه وزن بستههای محصول B کمتر از ۷۵۰ گرم است؟
زیرا مقدار Sig در سطر دوم با احتساب دادههای گمشده برای هر دو گروه کمتر از ۰٫۰۵ است. بنابراین فرض صفر رد می شود یعنی میانگین بستههای محصول B مخالف ۷۵۰ گرم است.
از طرف دیگر چون فاصله اطمینان شامل ناحیه منفی است مشخص می شود که تفاضل میانگین وزن بستهها از ۷۵۰ گرم دد ۹۵٪ مواقع کمتر از صفر است. به این ترتیب مشخص است که وزن بستهها کمتر از ۷۵۰ گرم است و دستگاههای مربوط به بستهبندی باید تعمیر و تنظیم شوند.
رسم نمودار خطی در SPSS
تعریف نمودارهای خطی (line charts) :
در نمودارهای خطی شاخص آماری به شکل خط در سطوح متغیرهای طبقه ای ارائه می شود.گاهی داده ها به جای اینکه کمیت پیوسته باشند مانند وزن، شمارشی هستند مانند تعداد دندانهای خراب، تعداد فرزندان، تعداد حوادث رانندگی در روز، میزان بارندگی سالهای مختلف. اگر تعداد مقادیر متمایز زیاد نباشد برای ساختن توزیع فراوانی به جای انکه ردهها را فواصل منظم در نظر بگیریم هر مقدار به عنوان یک رده به کار میرود.
حسن نمودار خطی :
در این است که می توان اثرات تعاملی متغیرهای طبقه ای را بر روی متغیرهای وابسته مشاهده کرد و برای متغییر های کمی مناسب است.
مقادیر متمایز به صورت نقاط روی محور افقی مشخص شده و سپس از نقاط حاصل، خط هایی عمود بر محور رسم می شود به طوریکه ارتفاع هر یک برابر با فراوانی نسبی مقدار مربوطه باشد.
در این حالت، خطوط جایگزین مستطیل ها می شوند تا بر این موضوع تاکید شود که فراوانی ها واقعا روی فاصله پخش نشده اند.
نکته :
برای اطمینان از صحت و درستی نرمال بودن توزیع فراوانی باید در خروجی spss مقادیر پارامترهای skewenss (چولگی) و kurtosis (کشتاوری) را بررسی کنید:
- اگر مقدار kurtosis یک عدد مثبت باشد، داده ها دارای یک توزیع نرمال با ارتفاع بالا هستند.
- اگر مقدار kurtosis یک عدد منفی باشد، داده ها را یک توزیع نرمال با ارتفاع پایین هستند.
- اگر مقادیر kurtosis و skewenss اختلاف زیادی از عدد ۵ داشته باشند، داده ها دارای توزیع نرمال نیستند
رسم نمودار خطی در spss
graphs/Legacy dialogs سپس line و روی کادر باز شده line charts باز می شود این نمودار به سه شکل زیر می باشد:
۱- نمودار ساده Simple
۲- نمودار چند گانه Multiple : برای نمایش توزیع دو متغییر نسبت به هم استفاده می شود.
۳- نمودار تکه خطی drop-line : که کمیه و بیشینه دو متغییر نسبت به هم نمایش می دهد.
۴- یکی از سه حالت فوق انتخاب کرده سپس define کلیک کرده و کادر مربوط به آن باز می شود
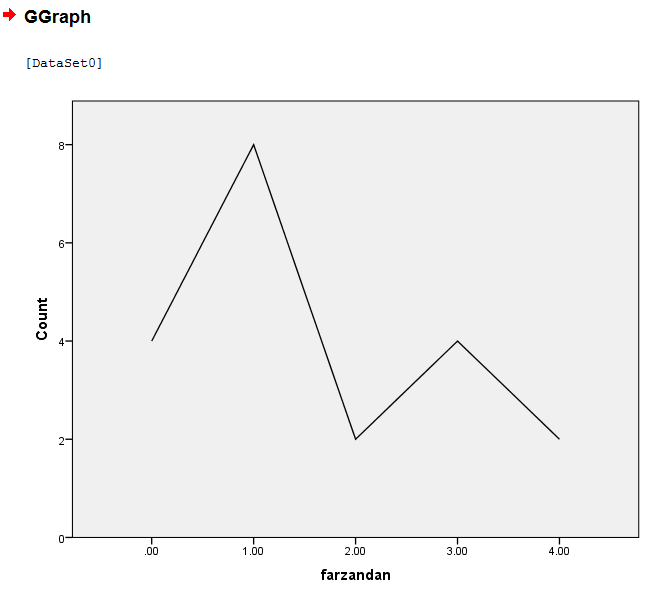
برای مثال : تعداد فرزندان در هر خانوار را ثبت نموده ایم و نمودار خطی حاصل از آن را ترسیم می نماییم.
Graphs> chart builder > ok
و در بخش نمودارها Line را انتخاب می نماییم. و متغیر مورد نظر را کشیده و به بخش پایین می بریم.
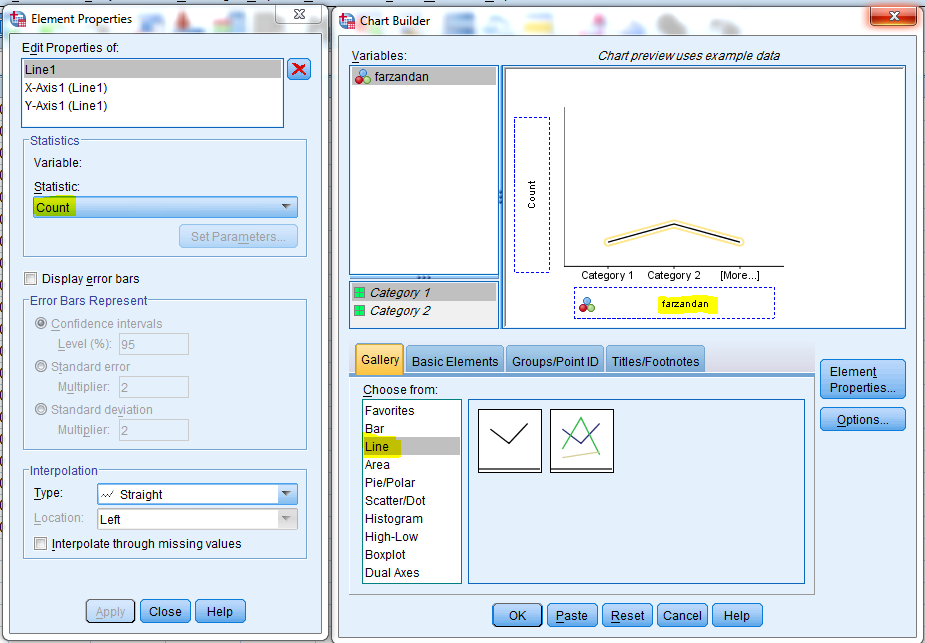 OK کرده و نمودار حاصل بدست میاد. در جدول سمت چپ Statistics گزینه های مختلف را میتوان انتخاب کرد. Count فراوانی را در نمودار ترسیم میکند و Percentage فراوانی نسبی را در نمودار می دهد. بعد از انتخاب گزینه مد نظر در Statistic باید گزینه Apply را کلیک کرد.
OK کرده و نمودار حاصل بدست میاد. در جدول سمت چپ Statistics گزینه های مختلف را میتوان انتخاب کرد. Count فراوانی را در نمودار ترسیم میکند و Percentage فراوانی نسبی را در نمودار می دهد. بعد از انتخاب گزینه مد نظر در Statistic باید گزینه Apply را کلیک کرد.
مثال:
منوی Analyze زیر منوی General Linear Model و زیرمنوی Repeated Measures چنین نموداری وجود دارد.
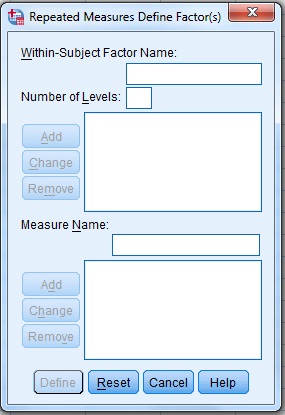
مثلا شما از یک متغیر کمی چندحالته (مثل سطح تحصیلات) ۲ الی ۲۹ نمونه دارید و میخواهید روند آنها را با نمودار خطی در SPSS محاسبه کنید، بنابراین مسیر بالا را طی کرده و در جعبه گفتگوی نمایان شده، تعداد نمونه ها را وارد کرده و Add و Define کنید.
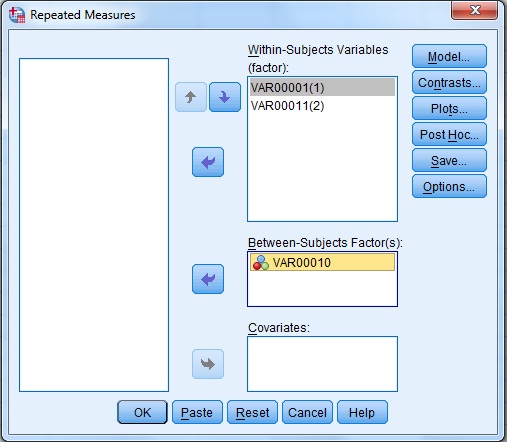
پس از آن همۀ نمونه ها را به بخش Within subject variablesو متغیر کیفی را به بخش Between subject variables انتقال داده و جعبه گفتگوی Plots را انتخاب کنید.
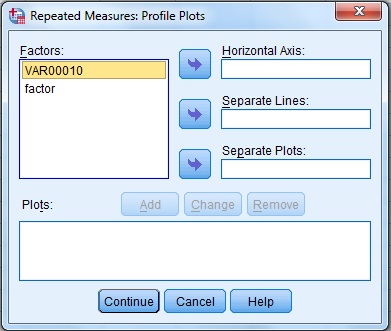
در مرحله باید متغیر Factor1 را به Separate Lines و متغیر کیفی را به Horizontal Axis منتقل کرده، Add و Continue نمایید. درنهایت Ok کنید.
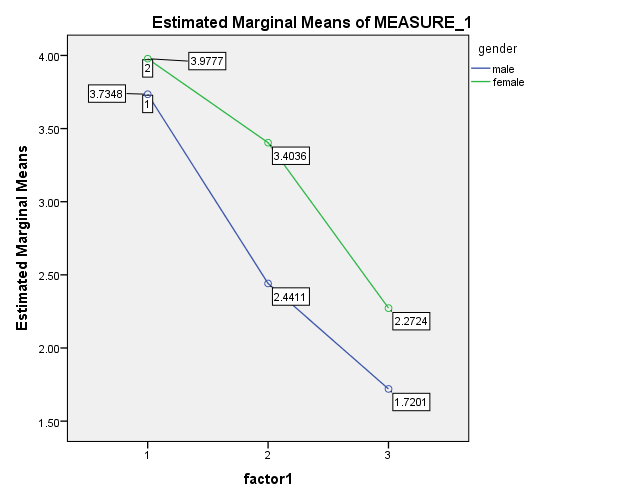
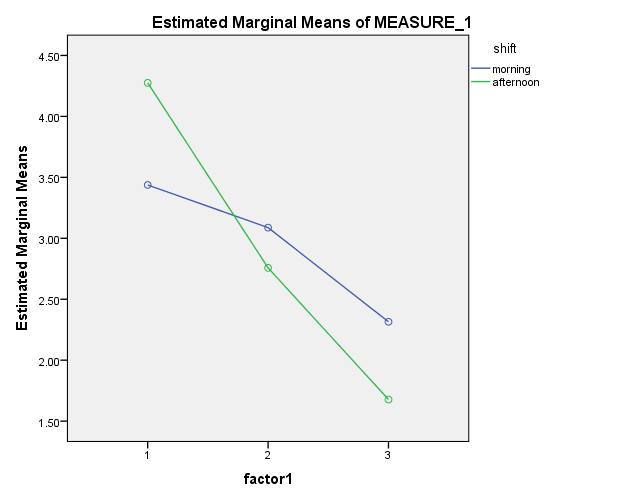
برای ساخت نمودارهای تعاملی کافی است به جای فعال نمودن گزینه ی Simple از گزینه ی Multiple استفاده شود و جهت بررسی اثرات تعاملی متغیرهای مستقل، باید دو متغیر مستقل را به دلخواه یک در جعبه ی Category Axisو دیگری را در جعبه ی Define line by قرارد هید.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
نحوه رسم نمودار میله ای در spss
نمودار ستونی شامل مجموعه ای از ستون هاست که با فاصله یکنواختی در کنار هم قرار می گیرند و هر ستون مختصّ یک طبقه از متغیر و طول آن متناسب با فراوانی یا درصد آن طبقه است.
نمودار ستونی برای متغیرهای کیفی (اسمی و ترتیبی) به کار می رود، اما برای متغیر کمّی که تعداد طبقات آن کم باشد هم قابل استفاده است.
به عنوان مثال چنانچه متغیری به نام تعداد فرزند داشته باشیم و در نمونه نهایی تعداد فرزندان هر خانواده از ۱ تا ۵ فرزند باشد و در واقع تعداد فرزندان شامل ۵ طبقه باشد بازهم می توانیم از این نمودار استفاده کنیم. در مثال کتاب، می توان برای متغیرهای تحصیلات پدر، قومیت و درآمد اقدام به ترسیم نمودار ستونی نمود.
نحوه رسم نمودار میله ای در spss
در این نوع نمودار، هر میله متناظر با یک رده از توزیع کیفی است.
(تفاوت )در آرایش میله ها باید جنبه های مختلفی را مورد توجه قرار داد:
- میله ها فقط در طول با هم تفاوت دارند و نه در پهنا.
- فضایی بین دو میله متوالی منظور شده است تا تعیین میله را با نشان آن ساده تر کند.
- برای تسهیل تحلیل، میله ها به ترتیب بزرگی رده بندی می شوند، که ممکن است کاهشی یا افزایشی باشد.
- وقتی مقایسۀ تصویری دو یا چند توزیع کیفی مورد نظر باشد، اغلب می توان نمودارهای میله ای آن ها را ترکیب کرد.
مثال:
توزیع کیفی شرکت ها با توجه به نوع صنعت به صورت جدول ۲-۳ رده بندی شده اند.

مراحل رسم نمودار میله ای (ستونی) در spss
۱- داده ها را به spss معرفی کنید.
۲- دستور Tranform > compute variable…را اجرا کنید.
۳- در ناحیۀ target variable (متغیر هدف)، از پنجرۀ ، متغیری به نام PCCount (درصد تعداد شرکت) تعریف کنید.
۴- در ناحیۀ Numeric Expression (عبارت عددی) جمله را به صورت (CCount)/ 383 تکمیل کنید، شکل ۵-۳٫

۱- در پنجرۀ compute variable روی ok کلیک کنید. متغیر PCCount در پنجرۀ spss ایجاد می شود.
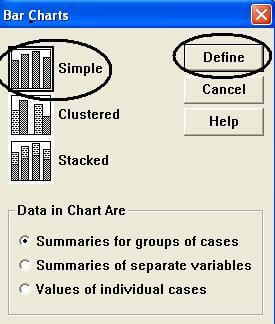
۲- دستور Graphs > Legacy Dialogs > Bar …را اجراکنید.
۳- مطمئن باشید در پنجرۀ Bar Charts (نمودارهای میله ای) عبارت Simple انتخاب شده است (در این حالت دور نماد مربوطه، یک کادر مربعی سیاه رنگ نشان داده می شود.
۴- با کلیک دکمۀ Define (تعریف)، پنجرۀ define simple bar: summaries of Groups of cases را باز کرده و عبارت PCCount را به ناحیۀ category Axis (محور طبقه بندی) منتقل کنید، شکل ۶-۳٫
۵- روی دکمۀ ok کلیک کنید، خروجی ۲-۳٫
توجه شود:
برای رسم نمودار «میله ای خوشه ای» (clustered Bar)، در پنجرۀ bar charts، نوع clustered را انتخاب کنید.
برای رسم نمودار «میله ای انباشته ای» (stacked bar) در پنجرۀ bar charts نوع stacked را انتخاب کنید.
فرض کنید یک نظر سنجی در مورد سبک فیلم مورد علاقه افراد، انجام دادهاید تا بدانید که کدام سبک فیلم طرفدار بیشتری دارد:
| جدول سبک فیلمهای مورد علاقه | ||||
| کمدی | اکشن | رمانتیک | درام | علمی-تخیلی |
|---|---|---|---|---|
| ۴ | ۵ | ۶ | ۱ | ۴ |
این جدول را میتوانیم روی یک نمودار میلهای به شکل زیر نمایش دهیم:
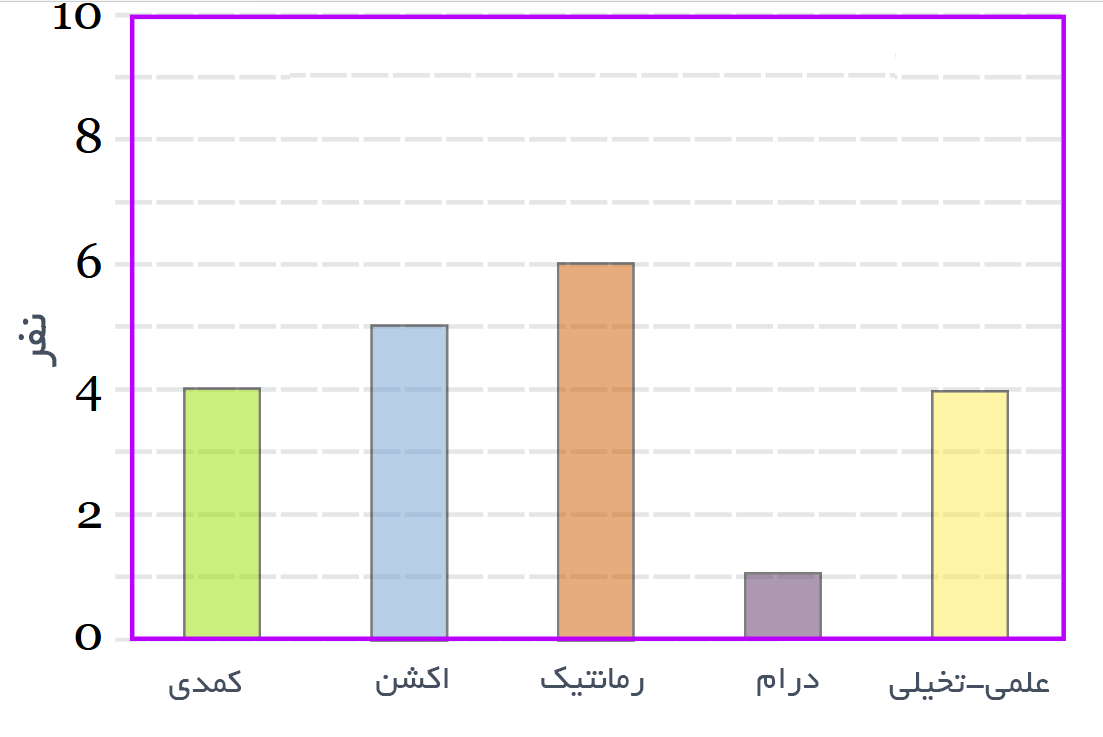
این روشی بسیار خوب برای نمایش اندازههای نسبی است، چون میتوانیم با نگاهی مختصر دریابیم که کدام سبک فیلمها طرفدار بیشتر و کدام ها طرفدار کمتری دارند. همچنین از نمودارهای میلهای میتوانیم برای نمایش اندازه نسبی بسیاری از چیزها، مانند مدل ماشینی که مردم استفاده میکنند، یا تعداد مشتریان یک مغازه در روزهای مختلف و یا موارد بیشمار دیگر استفاده کنیم.
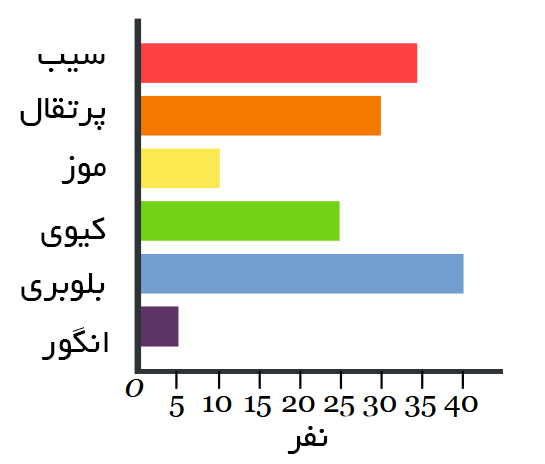
مثال: بهترین میوه
نتیجه یک نظرسنجی از ۱۴۵ نفر با سوال «کدام میوه از نظر شما بهترین است؟» به صورت زیر بوده است:
| میوه: | سیب | پرتقال | موز | کیوی | بلوبری | انگور |
| نفر: | ۳۵ | ۳۰ | ۱۰ | ۲۵ | ۴۰ | ۵ |
نمودار میلهای دادههای فوق به صورت زیر است:
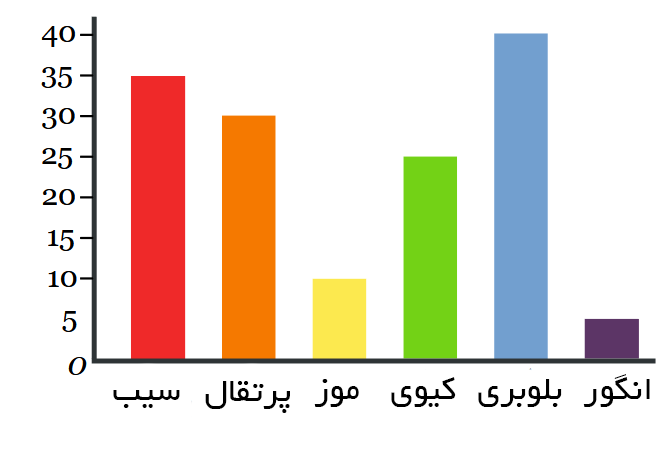
این گروه از مردم فکر می کنند که بلوبری بهترین میوه است. نمودار های میلهای میتوانند مانند تصویر زیر به صورت افقی نیز باشند:
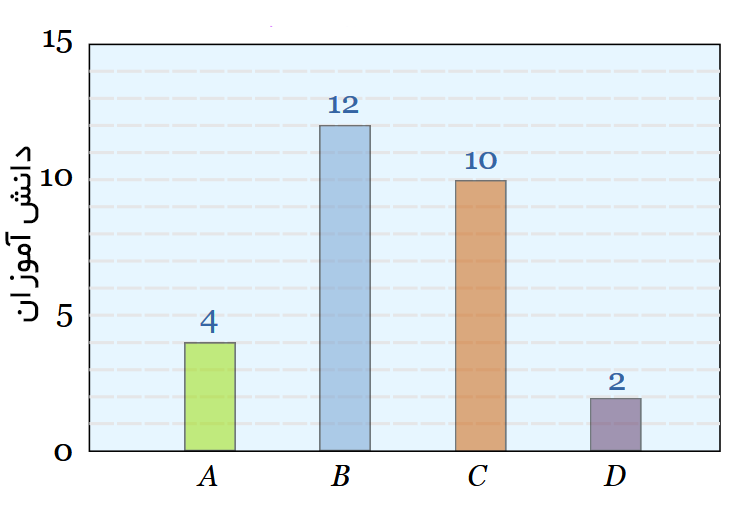
مثال: نمرات دانشآموزان
در یک امتحان، این تعداد از دانش آموزان، نمرات زیر را کسب کردهاند:
| نمره: | A | B | C | D |
| تعداد دانشآموز: | ۴ | ۱۲ | ۱۰ | ۲ |
و نمودار میلهای نیز چنین است:
هیستوگرامها در مقابل نمودارهای میلهای
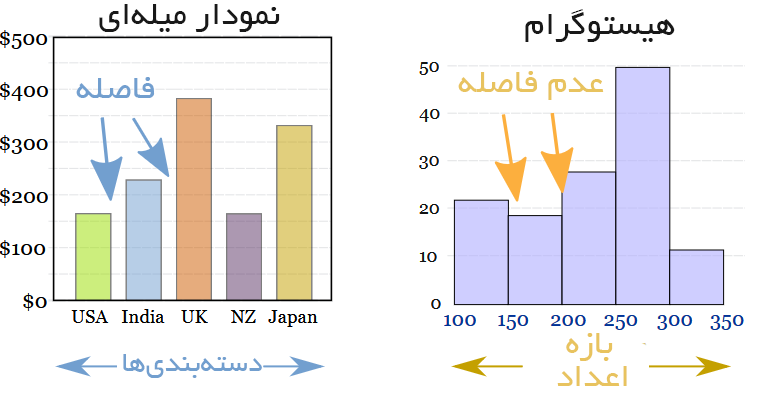
نمودار های میلهای در مواردی مناسب هستند که دادهها دستهبندی شده باشند، مانند کمدی، درام و غیره. اما اگر دادههای پیوستهای مانند قد یک شخص دارید بهتر است از هیستوگرام استفاده کنید. همچنین به طور معمول بین ستونها در نمودارهای میلهای فواصل مناسبی قرار میگیرند تا شبیه هیستوگرام نباشند و باعث اشتباه نشوند.
نکته مهم:
نمودار دایرهای در spss
نمودار یک روش نمایش گرافیکی برای دادهها است.وقتی به دلایلی نتوانیم داده ها را به صورت «کمی» مشخص کنیم، مثلا در مورد منابع انرژی که به رده های زغال، گاز طبیعی، نفت خام و غیره تقسیم می شود، باز هم نمایش نموداری گویاتر و نمایان تر از جدول است. توزیع مقدار کل روی رده ها، اغلب به صورت «نمودار دایره ای» نشان داده می شود. نمودار دایره ای یک نمودار ویژه است که از قطاعهای دایرهای برای نشان دادن اندازه نسبی دادهها استفاده میکند. ساده ترین تمثیل برای نمودار دایرهای، تشبیه آن به یک پیتزا است. بدین ترتیب میتوانید قاچهای پیتزا را قطاعهای نمودار در نظر بگیرید. برای توضیح بیشتر مثالی را در ادامه ارائه کردهایم.
مثال: فرض کنید که یک نظرسنجی از دوستانتان می کنید که بفهمید از کدام سبک فیلم بیشتر خوششان می آید.
نتایج چنین است:

می توانید این داده ها را به صورت نمودار دایره ای رسم کنید:

این روش، راه حل خوبی برای نمایش اندازههای مرتبط با هم است. در این روش نمایش، با یک نگاه میتوان فهمید کدام سبک فیلم بیشتر از همه و کدام کمتر از همه مورد پسند بوده است. شما نیز میتوانید برای دادههای خودتان چنین نموداری را رسم کنید.
مراحل رسم نمودار دایره ای در spss
۱- در پایین پنجرۀ spss روی عبارت variable view (نمای متغیر) کلیک کنید تا پنجرۀ مربوطه باز شود.
در این پنجره دو متغیر به نام های resources (منابع) و energy (انرژی) ایجاد کنید.
در ستون values (مقادیر) مربوط به پارامتر Energy (انرژی)، «برچسب» (lable) ها را مشابه شکل ۷-۳ تعریف کنید.

۱- با کلیک روی Data view، داده ها را به صورت زیر به spss معرفی کنید، شکل ۸-۳٫
۲- دستور Graphs > legacy dialogs > pie… را اجرا کنید.
۳- در پنجرۀ pie charts (نمودارهای دایره ای) گزینۀ values of individual cases (مقادیر جداگانه هر یک از موارد) را انتخاب کنید
۱- روی دکمۀ Define (تعریف شود) کلیک کنید تا پنجرۀ define pie: values of Indevidual cases باز شود.
در این پنجره متغیر را به ناحیۀ مستطیلی slice Represents (نمایش قاچ ها) منتقل کنید.
با انتخاب گزینۀ variable از ناحیۀ slice labels (برچسب های قاچ)، متغیر energy را به کادر مستطیلی موجود منتقل کنید، شکل ۱۰-۳٫
۲- روی دکمۀ ok کلیک کرده و خروجی حاصله را بررسی نمایید.
چگونه یک نمودار دایره ای رسم کنیم
ابتدا داده های خود را در یک جدول مانند بالا یادداشت کنید، سپس تمامی مقادیر را با هم جمع کنید تا مقدار کلی بدست آید.

سپس هر مقدار را بر جمع تقسیم کرده و آن را در ۱۰۰ ضرب می کنیم تا یک درصد بدست آید:

اکنون باید زاویه هر قسمت از دایره را پیدا کنید. یک دایره کامل ۳۶۰ درجه است، پس محاسبات را به صورت زیر انجام میدهیم:

اکنون آماده ایم که نمودار را رسم کنیم. ابتدا یک دایره رسم می کنیم. سپس با کمک نقاله، درجه ها را برای هر بخش رسم می کنیم. ما در تصویر زیر نخستین قطاع را نشان دادهایم. امتحان کنید که آیا میتوانید قطاعهای دیگر نمودار را رسم کنید؟

مثال های بیشتر
می توانید از نمودارهای دایرهای برای نمایش اندازه نسبی بسیاری از چیزها استفاده کنید، برخی از این موارد در ادامه فهرست شدهاند:
- نوع ماشینی که مردم سوار میشوند
- تعداد مشتریهای یک مغازه در روزهای مختلف
- این که کدام نوع موسیقی طرفدار بیشتری دارد.
مثال: نمرات دانشآموزان
در جدول زیر نشان داده شده که چه تعداد از دانشآموزان یک کلاس چه سطح نمرهای را در آزمون کسب کردهاند:

نمودار دایرهای دادههای فوق به صورت زیر است:

09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
تفسیر فرضیه بر اساس چارچوب نظری و مفهومی
تفسیر فرضیه بر اساس چارچوب نظری و مفهومی
هر پژوهش دارای یک چارچوب نظری یا مفهومی است. فرضیه های از چارچوب نظری، پیشینه های تحقیق و بر اساس مشاهدات محقق تدوین شده است باید بر همان اساس توصیف و تبیین شود.
مثال نگرش دانشجویان به رسانه ملی
در یک پژوهش نگرش دانشجویان دانشگاه های تهران به رسانه ملی در دست بررسی است.
مرحله ۱: تشخیص متغیرها
(وابسته: نگرش در سه بعد ۱- = نگرش منفی، ۰ = نگرش خنثی و ۱+ = نگرش مثبت این متغیر از لحاظ سطح سنجش ترتیبی است. متغیر مستقل: جنسیت در دو مقوله ۱ = مرد و ۲ = زن، این متغیر از لحاظ سطح سنجش اسمی است)
مرحله ۲: تشخیص آزمون مربوطه
با توجه به اینکه یکی از متغیرها اسمی و دیگری ترتیبی است آزمون مناسب آن خی دو می باشد.
مرحله ۳: تدوین فرضیه
فرضیه H0: به نظر می رسد نگرش دانشجویان دانشگاه های تهران در بین دختران و پسران دانشجو تفاوت ندارد.
فرضیه H1: به نظر می رسد نگرش دانشجویان دانشگاه های تهران در بین دختران و پسران دانشجو تفاوت دارد.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی