گروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشیگروه پژوهشی آینده
تهیه و انجام طرحهای پژوهشینمودار دایرهای در spss
نمودار یک روش نمایش گرافیکی برای دادهها است.وقتی به دلایلی نتوانیم داده ها را به صورت «کمی» مشخص کنیم، مثلا در مورد منابع انرژی که به رده های زغال، گاز طبیعی، نفت خام و غیره تقسیم می شود، باز هم نمایش نموداری گویاتر و نمایان تر از جدول است. توزیع مقدار کل روی رده ها، اغلب به صورت «نمودار دایره ای» نشان داده می شود. نمودار دایره ای یک نمودار ویژه است که از قطاعهای دایرهای برای نشان دادن اندازه نسبی دادهها استفاده میکند. ساده ترین تمثیل برای نمودار دایرهای، تشبیه آن به یک پیتزا است. بدین ترتیب میتوانید قاچهای پیتزا را قطاعهای نمودار در نظر بگیرید. برای توضیح بیشتر مثالی را در ادامه ارائه کردهایم.
مثال: فرض کنید که یک نظرسنجی از دوستانتان می کنید که بفهمید از کدام سبک فیلم بیشتر خوششان می آید.
نتایج چنین است:

می توانید این داده ها را به صورت نمودار دایره ای رسم کنید:

این روش، راه حل خوبی برای نمایش اندازههای مرتبط با هم است. در این روش نمایش، با یک نگاه میتوان فهمید کدام سبک فیلم بیشتر از همه و کدام کمتر از همه مورد پسند بوده است. شما نیز میتوانید برای دادههای خودتان چنین نموداری را رسم کنید.
مراحل رسم نمودار دایره ای در spss
۱- در پایین پنجرۀ spss روی عبارت variable view (نمای متغیر) کلیک کنید تا پنجرۀ مربوطه باز شود.
در این پنجره دو متغیر به نام های resources (منابع) و energy (انرژی) ایجاد کنید.
در ستون values (مقادیر) مربوط به پارامتر Energy (انرژی)، «برچسب» (lable) ها را مشابه شکل ۷-۳ تعریف کنید.

۱- با کلیک روی Data view، داده ها را به صورت زیر به spss معرفی کنید، شکل ۸-۳٫
۲- دستور Graphs > legacy dialogs > pie… را اجرا کنید.
۳- در پنجرۀ pie charts (نمودارهای دایره ای) گزینۀ values of individual cases (مقادیر جداگانه هر یک از موارد) را انتخاب کنید
۱- روی دکمۀ Define (تعریف شود) کلیک کنید تا پنجرۀ define pie: values of Indevidual cases باز شود.
در این پنجره متغیر را به ناحیۀ مستطیلی slice Represents (نمایش قاچ ها) منتقل کنید.
با انتخاب گزینۀ variable از ناحیۀ slice labels (برچسب های قاچ)، متغیر energy را به کادر مستطیلی موجود منتقل کنید، شکل ۱۰-۳٫
۲- روی دکمۀ ok کلیک کرده و خروجی حاصله را بررسی نمایید.
چگونه یک نمودار دایره ای رسم کنیم
ابتدا داده های خود را در یک جدول مانند بالا یادداشت کنید، سپس تمامی مقادیر را با هم جمع کنید تا مقدار کلی بدست آید.

سپس هر مقدار را بر جمع تقسیم کرده و آن را در ۱۰۰ ضرب می کنیم تا یک درصد بدست آید:

اکنون باید زاویه هر قسمت از دایره را پیدا کنید. یک دایره کامل ۳۶۰ درجه است، پس محاسبات را به صورت زیر انجام میدهیم:

اکنون آماده ایم که نمودار را رسم کنیم. ابتدا یک دایره رسم می کنیم. سپس با کمک نقاله، درجه ها را برای هر بخش رسم می کنیم. ما در تصویر زیر نخستین قطاع را نشان دادهایم. امتحان کنید که آیا میتوانید قطاعهای دیگر نمودار را رسم کنید؟

مثال های بیشتر
می توانید از نمودارهای دایرهای برای نمایش اندازه نسبی بسیاری از چیزها استفاده کنید، برخی از این موارد در ادامه فهرست شدهاند:
- نوع ماشینی که مردم سوار میشوند
- تعداد مشتریهای یک مغازه در روزهای مختلف
- این که کدام نوع موسیقی طرفدار بیشتری دارد.
مثال: نمرات دانشآموزان
در جدول زیر نشان داده شده که چه تعداد از دانشآموزان یک کلاس چه سطح نمرهای را در آزمون کسب کردهاند:

نمودار دایرهای دادههای فوق به صورت زیر است:

09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
تفسیر فرضیه بر اساس چارچوب نظری و مفهومی
تفسیر فرضیه بر اساس چارچوب نظری و مفهومی
هر پژوهش دارای یک چارچوب نظری یا مفهومی است. فرضیه های از چارچوب نظری، پیشینه های تحقیق و بر اساس مشاهدات محقق تدوین شده است باید بر همان اساس توصیف و تبیین شود.
مثال نگرش دانشجویان به رسانه ملی
در یک پژوهش نگرش دانشجویان دانشگاه های تهران به رسانه ملی در دست بررسی است.
مرحله ۱: تشخیص متغیرها
(وابسته: نگرش در سه بعد ۱- = نگرش منفی، ۰ = نگرش خنثی و ۱+ = نگرش مثبت این متغیر از لحاظ سطح سنجش ترتیبی است. متغیر مستقل: جنسیت در دو مقوله ۱ = مرد و ۲ = زن، این متغیر از لحاظ سطح سنجش اسمی است)
مرحله ۲: تشخیص آزمون مربوطه
با توجه به اینکه یکی از متغیرها اسمی و دیگری ترتیبی است آزمون مناسب آن خی دو می باشد.
مرحله ۳: تدوین فرضیه
فرضیه H0: به نظر می رسد نگرش دانشجویان دانشگاه های تهران در بین دختران و پسران دانشجو تفاوت ندارد.
فرضیه H1: به نظر می رسد نگرش دانشجویان دانشگاه های تهران در بین دختران و پسران دانشجو تفاوت دارد.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی
شاخصهای معیار پراکندگی در تحلیل آماری با spss
معیارهای پراکندگی
جهت متغیرهای کمی شاخصهای پراکندگی به صورت زیر میباشد:
1- واریانس و انحراف معیار:
میانگین مربع پر کاربردترین شاخص پراکندگی است. به عبارت دیگر، واریانس به معنی میانگین مربع فاصلهی مقادیر یک متغیر از میانگین آن متغیر است که فرمول محاسبهی آن به بصورت :
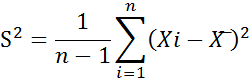
2- ضریب تغیرات:
ضریب تغییرات به واحدی که متغیر مربوط به آن اندازهگیری شده است، بستگی ندارد و میتوان پراکندگی دو متغیر متفاوت را با هم مقایسه نمود.
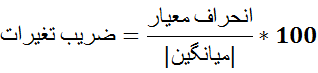
3- نمرات استاندارد:
جهت مشخص کردن موقعیت نمره یک فرد نسبت به نمرات دیگر افراد نمونه نمرات را استاندارد میکنیم. ابتدا نمره مشاهده شده را از میانگین کسر و سپس بر انحراف معیار تقسیم میکنیم.
– معیارهای شکل:
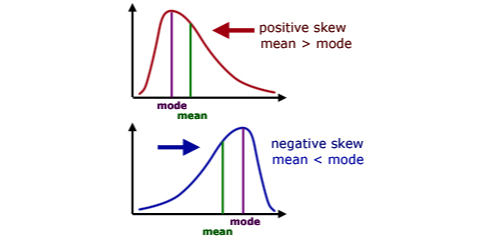
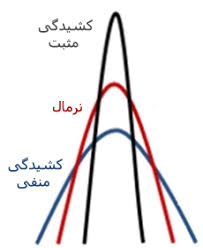
Skewness یا چولگی:
میزان عدم تقارن توزیع را اندازهگیری و بیان میکند، این میزان برای توزیع نرمال صفر است.
Kurtosis یاکشیدگی:
نشان دهنده قلهمندی و درجه اوج یک توزیع احتمالی است که برای توزیع نرمال عدد 3 است.
اگر بیشتر از 3 شود توزیع تیزتر از نرمال است.
اگر کمتر از 3 شود توزیع پهن تر از نرمال است.
Descriptive Statistics:
از این منو جهت محاسبه آمارههای توصیفی، تشکیل جداول فراوانی و جداول توافقی استفاده میشود. فرمانهای این منو به شرح زیر میباشد:
1- فرمان Frequencies فراوانی
2- فرمان Descriptive توصیفی
3- فرمان… Explore
4- جدول توافقی Crosstabs
از این فرمان جهت تشکیل جداول فراوانی متغیرهای اسمی و رتبه ای استفاده میشود. همچنین از این جدول، جهت متغیر کمی نیز استفاده می شود ولی لازم است آن متغیر را مجدد کدگذاری کنیم.
برای اجرای این فرمان، از منوی Analyze به ترتیب زیر منوهای Descriptive Statistics و Frequencies را انتخاب نمایید تا کادر زیر نمایان شود:
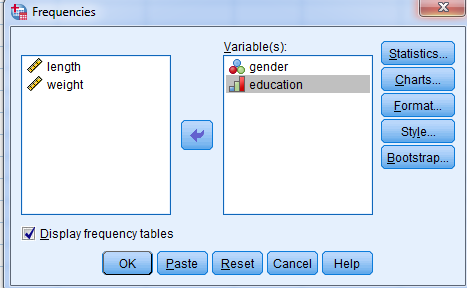
اسامی متغیرها در سمت چپ، فهرست شدهاند یک یا چند متغیر را به سمت راست منتقل کنید.
با کلیک روی دکمهی Statistics… کادر زیر نمایان میشود.
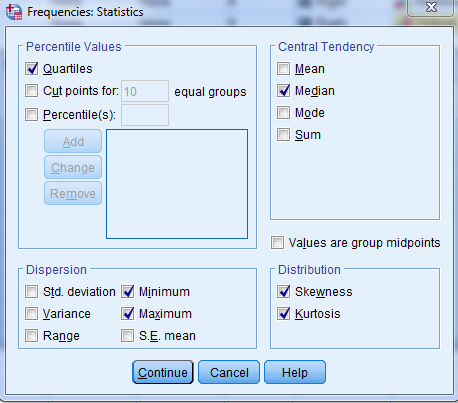
که دارای 4 قسمت میباشد.
در قسمت percentile values میتوانید( چارکها، صدکها و نقاط برش) را انتخاب نمایید.
در قسمت Central Tendency میتوانید شاخصهای( مرکزی میانگین، میانه، مد، مجموع )را انتخاب کنید. در قسمت Dispersion میتوانید شاخصهای پراکندگی ( مینیمم، ماکزیمم، واریانس، انحراف معیار، دامنه و خطای استاندارد)را بسته به نیاز انتخاب کرد.
در قسمت آخر Distribution میتوان مقادیر(چولگی و کشیدگی)را انتخاب کرد. روی دکمهی Continue کلیک کنید تا به کادر قبل بازگردید. روی دکمهی …Charts کلیک کنید تا کادر زیر نمایان شود:
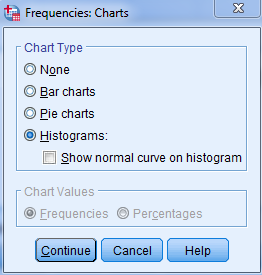
شامل دو قسمت است که به شرح آن میپردازیم:
قسمت اول Chart Type شامل چهار گزینه با انتخاب گزینهی None هیچ نموداری رسم نمیشود، با انتخاب گزینهی Bar charts نمودار میله ای، Pie charts نمودار دایرهای و Histograms نمودار هیستوگرام(مستطیلی) رسم میشود.
بعد از انتخاب گزینهی هیستوگرام، گزینهی With normal curve فعال میشود که با تیک زدن آن یک منحنی نرمال روی نمودار هیستوگرام نمایش مییابد.
در قسمت دوم، یعنیChart Values میتوان نوع نمایش مقادیر نمودار را تعیین کرد.
با انتخاب گزینهی Frequencies نمودار بر حسب مقادیر فراوانی و با انتخاب گزینهی Percentages نمودار بر حسب درصد فراوانی رسم میشود. این قسمت تنها زمانی فعال میشود که یکی از گزینههای Bar charts و Pie charts را انتخاب کرده باشید. اکنون روی دکمه Continue کلیک کنید تا به کادر قبل بازگردید.
توجه کنید که اگر تیک مقابل گزینه Display Frequency tables را در کادر Frequencies بردارید، جدول فراوانی تشکیل نمیشود. پس از انتخاب گزینههای مورد نظر روی دکمه ok کلیک کنید تا خروجی نمایش یابد.
09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی
حالت های مختلف Recode در SPSS
حالت های مختلف Recode به این صورت است:
از دستور Recode به عنوان یک دستور اصلاح و آمایشی قبل از انجام آزمون های آماری استفاده می شود.
۱- کد گذاری مجدد بر روی متغیر موجود (Recode into Same Variables)
۲- کد گذاری مجدد بر روی متغیر جدید (Recode into Different Variables)
نحوه اجراء
۱- دستور Transform-> Recode into Different Variables… را اجراء می کنیم.

۲- متغیر یا متغیرهایی را که قصد کد گذاری مجدد آن ها را داریم، وارد کادر Numeric Variable-> Output Variable در سمت راست می کنیم. نام متغیر جدید مان را در کادر Name تایپ می کنیم. سپس دکمه Change را کلیک می کنیم تا این تغییر نام در کادر Numeric Variable-> Output Variable ظاهر شود.

۳- در پنجره کدها یا مقادیر جدید و قدیم (Old and New Values) مطابق شکل تغییرات را اعمال می کنیم. این پنجره برای آسانی آموزش به دو بخش تقسیم شده است.
در پنجره مقادیر جدید و قدیم بر حسب دامنه نمراتی که تعیین کرده ایم کدهای تغییر یافته هر طبقه را وارد می کنیم:
۰ تا ۱۰ – کد ۰ (نمره د)
۱۰ تا ۹۹/۱۳ – کد ۱ (نمره ج)
۱۴ تا ۹۹/۱۶ – کد ۲ (نمره ب)
۱۷ تا ۲۰ – کد ۳ (نمره الف)
به عنوان مثال برای طبقه آخر یا کد ۳ (و در کادر کدهای قدیم یا Old Value) به ترتیب زیر عمل می کنیم.
۴- دکمه Old and New Values… را کلیک می کنیم. در پنجره جدید، در کادر سمت چپ، کد قدیم (Old Value) و در کادر راست نیز کد جدید (New Value) را وارد و سپس دکمه Add را به ترتیب طبقات جدید می زنیم و همین طور تا آخر ادامه می دهیم چنانچه کد قدیم یک عدد گسسته بود، در این صورت گزینه Value در کادر بالا سمت چپ انتخاب می کنیم. اما اگر کد قدیم ما حالت طیف داشت، در آن صورت گزینه Range در کادر میانی سمت چپ را انتخاب می کنیم. در نهایت، دکمه Continue را کلیک می کنیم.
۵- دکمه Ok را کلیک می کنیم.

09357258425
www.pajuha.ir
info@pajuha.ir
سفارش ترجمه تخصصی
خروجی Frequencies در spss
خروجی Frequencies
جدول فراوانی چهار نوع کاربرد در spss دارد به شرح ذیل توضیح داده می شود.
توصیف خروجی spss اجراء دستور Statistics
Analysis⇒ Descriptive Statistics⇒ Frequencies ⇒ Statistics
۱- samplings: این آماره نشان می دهد از مجموع پاسخ گویان ۷۴۹ نفر، ۹ نفر سن خود را به هر دلیلی بیان نکرده اند.
۲- Central tendency: حاصل اجراء این گزینه انجام سه آماره گرایش مرکزی است. میانگین سنی نشان می دهد، پاسخ گویان ۳۴ سال و شش ماه (۵۱ درصد یک سال) سن دارد. میانه سنی نشان می دهد ۵۰ درصد جمعیت نمونه ۳۰ سال و هشت ماه دارند. همچنین بر اساس نما، اکثر پاسخ گویان ۲۲ ساله بوده اند. با توجه به تعریف جوانی جمعیت، شاخص های گرایش مرکزی نشان می دهد جمعیت مورد بررسی جوان هستند.
۳- dispersion: این آماره ها (انحراف استاندارد،واریانس، دامنه تغییرات، منیمم، ماکسیمم و انحراف متوسط میانگین) نشان می دهد توزیع نمونه یکنواخت نبوده و خیلی پراکنده هستند.
۴- distribution:مقدار آماره های کشیدگی و چولگی کمتر از قدر مطلق عدد ۲ می باشند. این مقدار نشان می دهد داده ها از توزیع تقریباً نرمال برخوردار هستند.




 سن: (توصیف سن پاسخ گویان بر اساس جدول)
سن: (توصیف سن پاسخ گویان بر اساس جدول)
در مجموع سن ۵/۱۱ درصد پاسخ گویان کمتر از ۲۰ سال، ۵/۱۳ درصد ۲۰ تا ۲۴ سال، ۱/۲۰ درصد ۲۵ تا ۲۹ سال، ۳/۲۰ درصد ۳۰ تا ۳۹ سال، ۱/۱۸ درصد ۴۰ تا ۴۹ سال و ۴/۱۵ درصد بیشتر از ۵۰ سال بوده است. ضمن این که ۱/۱ درصد پاسخ گویان (۹ نفر) سن خود را اظهار نکرده اند. میانگین سنی پاسخ گویان ۵۱/۳۴ بوده است. همچنین کمترین سن ثبت شده پاسخ گویان ۱۵ سال و بیشترین آن ۷۴ سال بوده است (جدول ۲).
 توصیف خروجی SPSS اجرای دستور chart
توصیف خروجی SPSS اجرای دستور chart
Analysis ⟹ Descriptive Statistics ⟹ Frequencies ⟹ chart
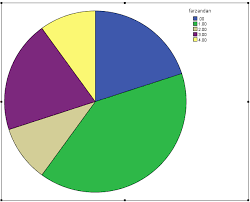
سن: (توصیف سن پاسخ گویان بر اساس نمودار)
در مجموع سن ۶/۱۱ درصد پاسخ گویان کمتر از ۲۰ سال، ۶/۱۳ درصد ۲۰ تا ۲۴ سال، ۳/۲۰ درصد ۲۵ تا ۲۹ سال، ۷/۲۰ درصد ۳۰ تا ۳۹ سال، ۳/۱۸ درصد ۴۰ تا ۴۹ سال و ۶/۱۵ درصد بیشتر از ۵۰ سال بوده است. ضمن اینکه ۱/۱ درصد پاسخ گویان (۹ نفر) سن خود را اظهار نکرده اند. میانگین سنی پاسخ گویان ۵۱/۳۴ بوده است. همچنین کمترین سن ثبت شده پاسخ گویان ۱۵ سال و بیشترین آن ۷۴ سال بوده است (نمودار).
 توصیف خروجی ارجای Format
توصیف خروجی ارجای Format
Analysis ⟹ Descriptive Statistics ⟹ Frequencies ⟹ format
در جدول زیر چهار نوع مرتب شدن جدول فراوانی داده های متغیر نشان داده شده است.
۱- این جدول بر اساس ارزش های متغیر به صورت صعودی مرتب شده است
۲- این جدول بر اساس ارزش های متغیر به صورت نزولی مرتب شده است
۳- این جدول بر اساس فراوانی داده ها به صورت صعودی مرتب شده است
۴- این جدول بر اساس فراوانی داده ها به صورت صعودی مرتب شده است

 خروجی Style و bootstrap
خروجی Style و bootstrap
این دو خروجی برای یادگیری ضرورت ندارند.
09357258425
info@pajuha.ir
سفارش ترجمه تخصصی